在使用 PostgreSQL 时,分区表可以有效管理和优化大规模数据表的存储和查询性能。在一些国产库中兼容了oracle的创建语法格式,有些仅支持语法存储还是pg,有些是连语法都未支持,在PG中创建分区的方法让oracle DBA可能有些难以适应,在PG中的分区分为parent/partitioned 和 child/partition tables , PostgreSQL支持range, list, hash分区。这里记录一些PG系使用过程中的注意事项。
如何使用 PostgreSQL 表分区
要在 PostgreSQL 中使用表分区,首先需要为表定义分区方案, 支持按 RANGE、LIST 和 HASH 进行分区,同样支持部分二级分区。
1,Range partition
create table xxx(
xxx,
...
date DATE NOT NULL
)
PARTITION BY RANGE (date);
CREATE TABLE xxx_q1 PARTITION OF xxx FOR VALUES FROM ('2024-01-01') TO ('2024-02-01'); -- >= < 注意避免分区gap
...
2, List partition
create table xxx(
xxx,
...
org text NOT NULL
)
PARTITION BY List(org);
CREATE TABLE xxx_heb PARTITION OF xxx FOR VALUES IN ('HEB');
...
3, Hash partition
create table xxx( xxx, ... num int NOT NULL ) PARTITION BY Hash(num); CREATE TABLE xxx_0 PARTITION OF xxx FOR VALUES WITH (MODULUS 10, REMAINDER 0); CREATE TABLE xxx_1 PARTITION OF xxx FOR VALUES WITH (MODULUS 10, REMAINDER 1); ...
分区策略数量
分区数量不宜过多或过少。分区过多可能导致管理复杂性和性能开销, 过多可能会带来的SQL 在父表的parse时间增加(但是也优于view 中select xxx union all select xxx …的解析时间, 问题案例),同时可能会产生运行时内存增加的影响。分区过少可能无法充分利用分区优势。
自动分区管理
数据库中如果分区表较多,有统一的分区粒度,或随着数据的增长和变化,您可能会发现手动创建和删除分区可能很复杂,我们在某运营商的项目每个月要几十万个分区维护,费时费力还可能出错,不过在oracle中支持interval partition,可以实现一些range partition的自动创建,后期版本还支持了autolist . 但是当前版本Pg中并不支持自动。但基于pg的部分国产库也支持了interval partition。对于数据的周期管理,制定数据保留策略,希望可以定期的清理历史分区降低存储成本,甚至优化部分查询需要扫描的数据量,从而提高查询性能。
在 PostgreSQL 中有几种方法可以实现自动分区管理。
1. crontab
如在linux上可以配置crontab写shell脚本定期执行。如批量创建
CREATE TABLE sales (
id BIGINT GENERATED ALWAYS AS IDENTITY,
date DATE NOT NULL,
store_id INTEGER NOT NULL,
amount NUMERIC NOT NULL
)
PARTITION BY RANGE (date);
# 增加5000分区
i=1; while [ $i -le 5000 ];
do
date_start=$(date +%Y_%m_%d -d "$(date) +$i day");
date_end=$(date +%Y_%m_%d -d "$(date) +$i day + 1 day");
SQLSTR="CREATE TABLE IF NOT EXISTS sales_$(date +%Y_%m_%d -d "$(date) +$i day") PARTITION OF sales FOR VALUES FROM ('$date_start') to ('$date_end');";
echo $SQLSTR;
psql anbob anbob -c "$SQLSTR";
((i++));
done;
# 分区清理
YEAR=$(date +%Y)
YEAR_MONTH=$(date +%Y_%m -d "$(date) -1 month")
echo $YEAR
echo $YEAR_MONTH
tbArray=$(psql -tc "\dt sales_$(($YEAR - 1))_*" | awk -F'|' '{print $2}')
for i in $(echo ${tbArray[@]}); do
psql -c "DROP TABLE IF EXISTS $i";
done
tbArray=$(psql -tc "\dt sales_${YEAR_MONTH}_*" | awk -F'|' '{print $2}')
for i in $(echo ${tbArray[@]}); do
psql -c "DROP TABLE IF EXISTS $i";
done
$ YEAR_MONTH=$(date +%Y_%m -d "$(date) +1 month")
$ psql anbob anbob -tc "\dt sales_${YEAR_MONTH}_*"
public | sales_2025_01_01 | table | anbob
public | sales_2025_01_02 | table | anbob
public | sales_2025_01_03 | table | anbob
public | sales_2025_01_04 | table | anbob
public | sales_2025_01_05 | table | anbob
public | sales_2025_01_06 | table | anbob
public | sales_2025_01_07 | table | anbob
public | sales_2025_01_08 | table | anbob
public | sales_2025_01_09 | table | anbob
public | sales_2025_01_10 | table | anbob
public | sales_2025_01_11 | table | anbob
public | sales_2025_01_12 | table | anbob
public | sales_2025_01_13 | table | anbob
public | sales_2025_01_14 | table | anbob
public | sales_2025_01_15 | table | anbob
public | sales_2025_01_16 | table | anbob
public | sales_2025_01_17 | table | anbob
public | sales_2025_01_18 | table | anbob
public | sales_2025_01_19 | table | anbob
public | sales_2025_01_20 | table | anbob
public | sales_2025_01_21 | table | anbob
public | sales_2025_01_22 | table | anbob
public | sales_2025_01_23 | table | anbob
public | sales_2025_01_24 | table | anbob
public | sales_2025_01_25 | table | anbob
public | sales_2025_01_26 | table | anbob
public | sales_2025_01_27 | table | anbob
public | sales_2025_01_28 | table | anbob
public | sales_2025_01_29 | table | anbob
public | sales_2025_01_30 | table | anbob
public | sales_2025_01_31 | table | anbob
$ psql -tc "\dt sales_$(($YEAR +1))_*"
public | sales_2025_04_02 | table | hg
public | sales_2025_04_04 | table | hg
当然自己再修改一下脚本和周期,增加写日志, 配置进crontab。
plpgsql批量
CREATE TABLE parent_table (
id SERIAL, --PRIMARY KEY
created_at DATE NOT NULL,
data TEXT
) PARTITION BY RANGE (created_at);
DO $$
DECLARE
start_date DATE := '2004-01-01'; -- 起始日期
end_date DATE := '2014-12-01'; -- 结束日期
partition_name TEXT;
partition_start DATE;
partition_end DATE;
BEGIN
WHILE start_date <= end_date LOOP
-- 定义分区名称和范围
partition_name := format('parent_table_%s', to_char(start_date, 'YYYYMMDD'));
partition_start := start_date;
partition_end := start_date + INTERVAL '1 DAY';
-- 创建分区表
EXECUTE format( 'CREATE TABLE IF NOT EXISTS %I PARTITION OF parent_table FOR VALUES FROM (''%s'') TO (''%s''); ', partition_name, partition_start, partition_end);
-- 移动到下一个月
start_date := start_date + INTERVAL '1 DAY';
END LOOP;
END;
$$;
在数据库中创建配置表,或创建成存储过程,在shell中调用或直接数据库调用,实现自动增加。
2. DB scheduler pg_cron扩展
pg_cron 扩展是一个 PostgreSQL 扩展,允许您直接从数据库内部安排和运行类似 cron 的作业。使用 pg_cron,您可以使用熟悉的类似 cron 的语法来安排作业,这些作业将直接在数据库内执行。这消除了对外部调度工具的需求,并简化了计划任务的管理。
-- create extension pg_cron
CREATE EXTENSION pg_cron;
-- create a pg_cron task and schedule monthly
SELECT cron.schedule('0 0 1 * *', $$SELECT xxx_mgr_partition();$$);
3, pg_partman 扩展
pg_partman 扩展是 PostgreSQL 的一个扩展,它为大型表提供了高级分区功能。它允许您根据时间间隔或其他条件自动管理分区,并提供了一组用于管理分区表的工具。可以使用 pg_partman 管理分区维护任务(例如创建和删除分区),以及自动执行在分区之间移动数据的过程。要使用 pg_partman,您需要安装扩展并使用 “partman.create_parent()” 函数创建一个分区表。
yum install pg_partman
CREATE SCHEMA partman;
CREATE EXTENSION pg_partman WITH SCHEMA partman;
-- 创建父表
CREATE TABLE sales (
...
order_date DATE NOT NULL,
...
)
PARTITION BY RANGE (date);
-- 使用 pg_partman 创建分区
SELECT partman.create_parent(
p_parent_table := 'public.sales',
p_control := 'order_date',
p_type := 'native', -- 使用原生分区
p_interval := 'monthly',
p_premake := 2
);
-- 使用pg_partman 配置保留周期
UPDATE partman.part_config SET retention = '12 month', retention_keep_table=false WHERE parent_table='public.sales';
-- 使用 pg_cron 设置每日维护任务
CREATE EXTENSION IF NOT EXISTS cron;
SELECT cron.schedule('0 0 * * *', $$SELECT partman.run_maintenance()$$);
4, pg_pathman 扩展
pg_pathman 是一个 Postgres Pro 扩展,可为大型分布式数据库提供优化的分区解决方案 ,值得注意的是,从 Postgres Pro 12 开始,不建议使用 pg_pathman。自 2019 年以来,它已被弃用。
动态分区创建允许您根据需要创建分区,而无需提前预先创建大量分区,从而有助于简化管理。这有助于降低存储成本,因为您仅在需要时创建分区,并且可以通过减少管理大量分区的开销来帮助提高性能。 有点接近于oracle interval partition的技术, 在插入时创建分区它可能会增加插入过程的开销,因为 PostgreSQL 必须执行额外的工作来创建分区并更新分区元数据。不建议在大规模生产中使用动态按需创建。支持外部表,支持在planner中做分区裁剪。
SELECT create_hash_partitions(
'abc', -- relation name
'id', -- partitioning key
3 -- number of partitions
);
SELECT create_range_partitions(
'abc', -- relation name
'dt', -- partitioning key
'2016-01-01'::date, -- start value
'1 month'::interval -- interval
);
SELECT append_range_partition('abc');
SELECT prepend_range_partition('abc');
SELECT add_range_partition('abc',
'2016-05-01'::date,
'2016-06-01'::date);
SELECT attach_range_partition('abc', 'some_table',
'2016-06-01'::date,
'2016-07-01'::date);
SELECT merge_range_partitions('abc_1', 'abc_2');
SELECT split_range_partition('abc_1', '2016-02-01'::date);
SELECT detach_range_partition('some_table');
SELECT replace_hash_partition('abc_0', 'some_table');
SELECT drop_range_partition('abc_0', true);
SELECT drop_partitions('parent_table', false);
SELECT parent, partition, range_min, range_max,
pg_size_pretty(pg_relation_size(partition)) AS size
FROM pathman_partition_list;
parent | partition | range_min | range_max | size
------------+--------------+-----------+-----------+------------
test_hash | test_hash_0 | | | 96 kB
test_hash | test_hash_1 | | | 88 kB
test_hash | test_hash_2 | | | 96 kB
test_hash | test_hash_3 | | | 96 kB
test_range | test_range_1 | 1 | 2001 | 72 kB
test_range | test_range_2 | 2001 | 4001 | 72 kB
test_range | test_range_3 | 4001 | 6001 | 72 kB
test_range | test_range_4 | 6001 | 8001 | 72 kB
test_range | test_range_5 | 8001 | | 8192 bytes
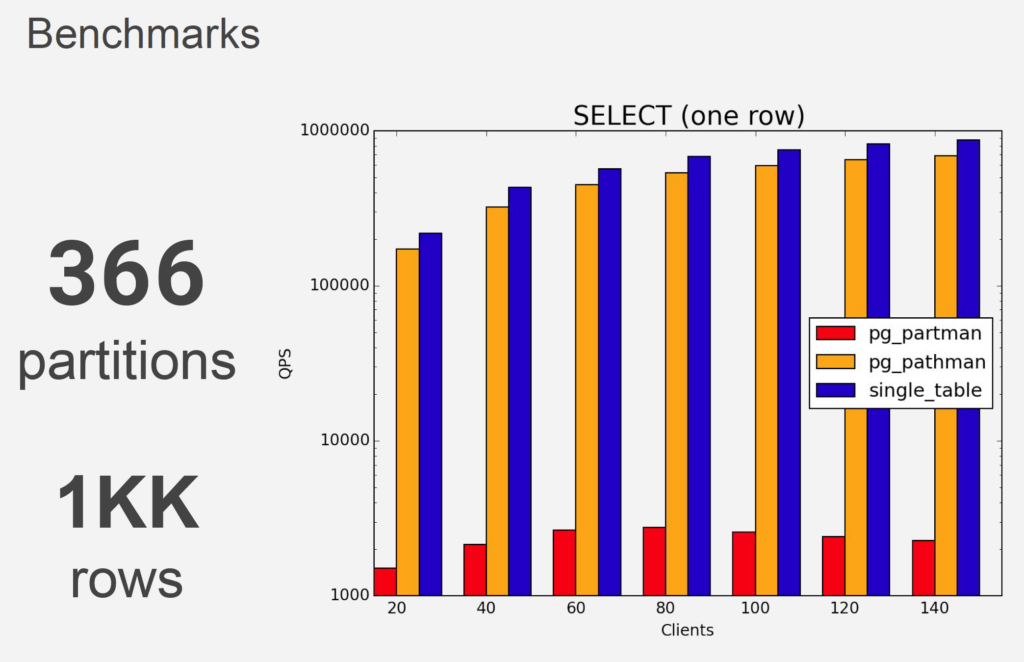
图来自postgresqlpro.ru测试