openGauss PBE 和enable_pbe_optimization 参数
几年前整理过<PostgreSQL 12 : Prepare statement和plan_cache_mode 参数>,在SQL使用 PBE(Parse Bind Execute) 时,如prepare statement, 如何生成gplan(通用执行计划)和cplan(定制执行计划), 及解析共享在如数据倾斜时可能存在的执行计划错误,前几天在opengauss系数据库做了切换后,较多SQL产生了错误的执行计划,因为错误的cost估算,有hash join 改成了nl join同样也是PBE的错误场景,仅记录。
参数enable_pbe_optimization
参数类型:布尔型
取值范围:
- on:表示优化器将优化PBE语句的查询计划,在FQS下选择gplan。 默认值
- off:表示不使用优化。
什么是PBE?
SQL TEXT在服务端执行要经过parse, analyze ,rewrite , plan, execute阶段,oracle有shared pool 用于缓存共享SQL, 而pg系中是进程级使用prepare 命令共享,来复用parse、analyze、rewrite阶段的工作,从而提升SQL Parse效率, 在OG中叫PBE (Prepare Bind Execute)。 java中调用可以是preparestatement class调用。
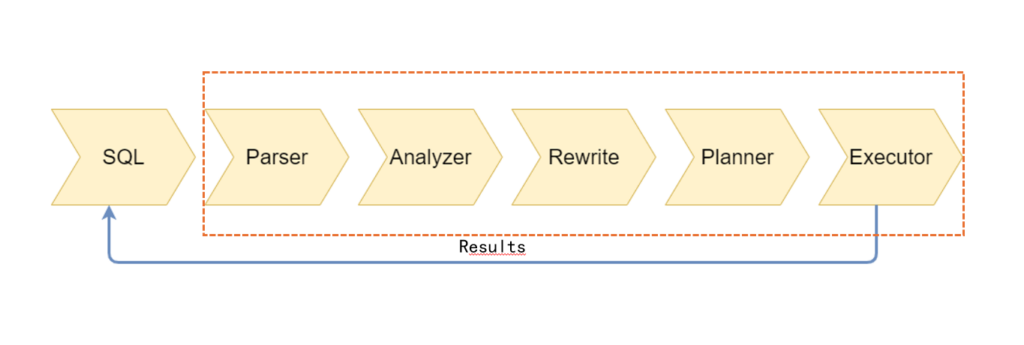
Postgresql SQL的不同时期之间的调用:
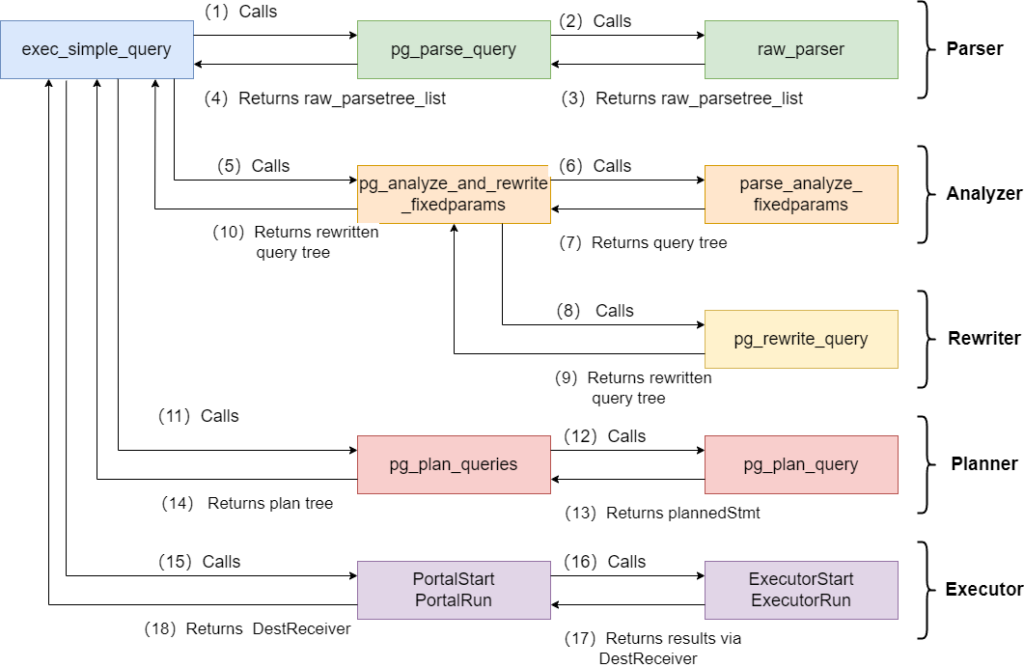
(图来自highgoDB)
PBE提升了SQL解析的效率,但是当数据有倾斜时,可能会产生错误的执行计划,在oracle同样存在,oracle引入了绑定变量窥探和自适应游标。在OpenGauss中目前还不未有相关技术,有两个参数与hint来控制。
plan_cache_mode这在Postgresql中同样存在。 另外是enable_pbe_optimization作为PBE优化的开关,关闭后配合plan_cache_mode模式,如5次cplan后判断使用gplan. 还有SQL HINT: /*+use_cplan */和/*+use_gplan */,及/*+ choose_adaptive_gplan */ 自适应管理
当数据倾斜时, 优化SQL级可以使用:
anbob=# create table t (a int, b int, c int); CREATE TABLE anbob=# prepare p as select /*+ use_cplan */ * from t where a = $1; PREPARE anbob=# explain execute p(1); QUERY PLAN ---------------------------------------------------- Seq Scan on t (cost=0.00..34.31 rows=10 width=12) Filter: (a = 1) (2 rows)
这样查看执行计划的变量为字面量,否则使用gplan,变量值为$N
anbob=# deallocate p; DEALLOCATE anbob=# prepare p as select /*+ use_gplan */ * from t where a = $1; PREPARE anbob=# anbob=# explain execute p(1); QUERY PLAN ---------------------------------------------------- Seq Scan on t (cost=0.00..34.31 rows=10 width=12) Filter: (a = $1) (2 rows)
注: 仅对papare SQL生效。

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~


对不起,这篇文章暂时关闭评论。