How to reduce space of the largest object (table system.logmnr_restart_ckpt$)in System Tablespace
Today, I noticed that the customer’s system tablespace usage is quite large, currently around 3.5TB. The largest object is the system.Logmnr_restart_ckpt$ table, which is already close to 2TB in size. The next largest is the aud$unified table used for unified auditing. In my blog yesterday 《Know more about Unified Auditing in Oracle 19c》, I documented the method for cleaning up the audit table. Today, I will focus on addressing the space usage of the system.Logmnr_restart_ckpt$ table.
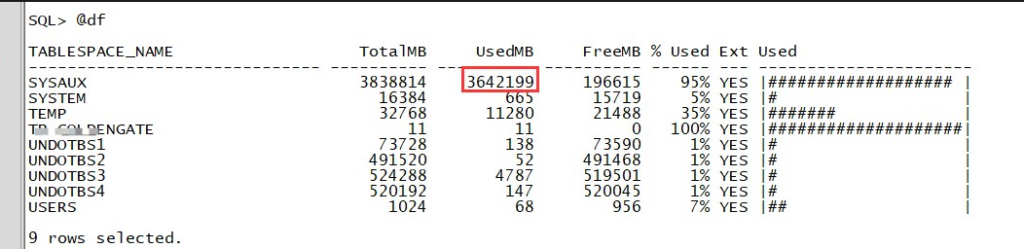
the largest object

Note:
the largetst object is table logmnr_restart_ckpt$ size is 2TB(include indexes).
what’s the logmnr_restart_ckpt$ table?
In Oracle, the LOGMNR_RESTART_CKPT$ table is an internal table used by the LogMiner utility. LogMiner is a tool provided by Oracle to mine historical data from archived redo logs. It allows you to extract and analyze changes made to the database over time, which can be useful for a variety of purposes, such as auditing, data recovery, and application development. The table stores checkpoint information that helps LogMiner resume processing from the point where it was previously interrupted. This allows LogMiner sessions to be restarted without having to reprocess all the redo logs from the beginning.
When you start a LogMiner session using commands like LOGMNR START, Oracle creates entries in the LOGMNR_RESTART_CKPT$ table to track the session’s progress. When you end a session using LOGMNR END, the entries are updated to reflect the final state of the session.
If you need to restart a LogMiner session, Oracle can use the information stored in LOGMNR_RESTART_CKPT$ to resume processing from the last checkpoint, ensuring that no redo log information is missed.
To reduce logmnr_restart_ckpt$ space
Periodically, the mining process checkpoints itself for quicker restart. These checkpoint information is maintained in the SYSAUX tablespace by default.
From Oracle 10.2 onwards, the purging of logmnr_restart_ckpt$ is done automatically by Oracle. There is a capture parameter checkpoint_retention_time that determines how frequently the purge occurs.
CHECKPOINT_RETENTION_TIME, controls the amount of checkpoint data that is retained by moving the FIRST_SCN of the capture process forward. When the checkpoint_retention_time is exceeded (default = 60 days), the FIRST_SCN is moved and the Streams metadata tables previous to this scn(FIRST_SCN) can be purged. Space in the SYSAUX tablespace should be reclaimed at this time.
SQL> select * from DBA_CAPTURE;
You can alter checkpoint_retention_time to lesser value to purge the metatdata tables more frequently using the following syntax :
exec dbms_capture_adm.alter_capture(capture_name =>'<name> ',CHECKPOINT_RETENTION_TIME=><days>);
You can then use the shrink command to manually free unused space both above and below the high water mark of the table.
alter table system.LOGMNR_RESTART_CKPT$ enable row movement; alter table system.LOGMNR_RESTART_CKPT$ shrink space ; alter table system.LOGMNR_RESTART_CKPT$ modify lob (CKPT_INFO) (shrink space); alter table system.LOGMNR_RESTART_CKPT$ disable row movement;
The index associated with the table can be shrunk using
alter index <index name> shrink space;
It is also useful to tune _checkpoint_frequency appropriately in order to minimise the checkpoint information stored and this should be mentioned. _checkpoint_frequency parameter control how often the logminer session associated to the capture is going to do a logminer checkpoint, a value of 10 means that after 10Mb of redo activity we do a logminer checkpoint.Using larger values can be reduce the number of Logminer checkpoint and therefore reduce the number of entries on logmnr_checkpoint_entries table and also reduce the consume and increase performance.
Capture Parameters
Set the following parameters after a capture process is created:
| Parameter &
Recommendation |
Values | Comment |
|---|---|---|
| _CHECKPOINT_FREQUENCY=500 | Default: 10 <10.2.0.4
Default 1000 in 10.2.0.4 |
Modify the frequency of logminer checkpoints especially in a database with significant LOB or DDL activity. Larger values decrease the frequency of logminer checkpoints. Smaller numbers increase the frequency of those checkpoints. Logminer checkpoints are not the same as database checkpoints. Availability of logminer checkpoints impacts the time required to recover/restart the capture after database restart. In a low activity database (ie, small amounts of data or the data to be captured is changed infrequently), use a lower value, such as 100.
A logminer checkpoint is requested by default every 10Mb of redo mined. If the value is set to 500, a logminer checkpoint is requested after every 500Mb of redo mined. Increasing the value of this parameter is recommended for active databases with significant redo generated per hour. It should not be necessary to configure _CHECKPOINT_FREQUENCY in 10.2.0.4 or higher |
<Troubleshooting RMAN-08137: WARNING: archived log not deleted> a deleted without UNREGISTER CAPTURE case.
References:
How to reduce the Highwater of LOGMNR_RESTART_CKPT$ (Doc ID 429599.1)
System.Logmnr_restart_ckpt$ Grows quite fast (Doc ID 735071.1)

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~


对不起,这篇文章暂时关闭评论。