Troubleshooting ‘local write wait’ wait event during Truncate table
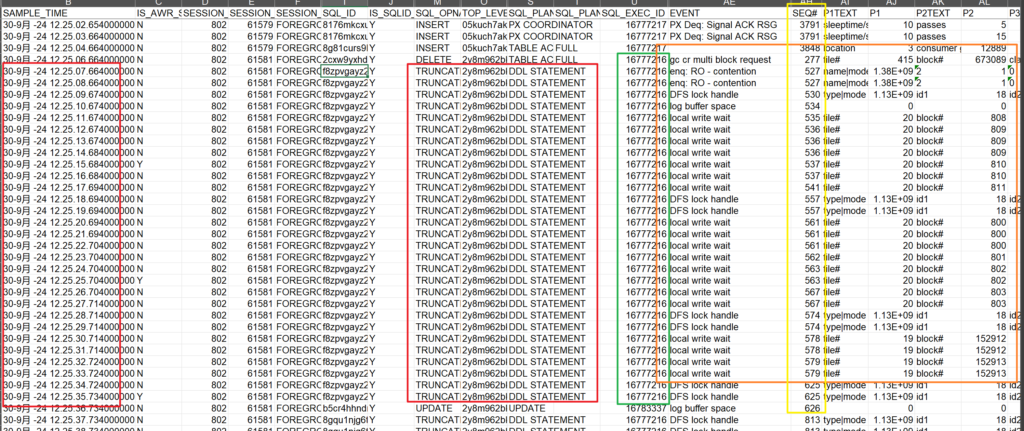
The combination of Local Write Wait response 18s time.
- local write wait occurs, as the name suggests, when the session is waiting for its own write operations. The RO enqueue is used to protect the buffer cache chain while it is scanned for dirty blocks in an object for the database writer to then write to the data files.
- enq: RO – fast object reuse occurs when a process waits to acquire the RO enqueue, in other words, while somebody else is truncating or dropping an object.
event “local write wait”
Basically ‘local write’ wait happens (as the name indicates) when the session is waiting for its local (means writes pending because of its own operation) write operation. This could happen typically if the underlying disc has some serious problems (one of the member disk crash in RAID-05 – for example, or a controller failure). You may see this during (rarely) Truncating a large table while most of the buffers of that table in cache. During TRUNCATEs the session has to a local checkpoint and during this process, the session may wait for ‘local write’ wait.
Truncate table slow
ASKTOM “Local Write Wait” wait event and truncate
truncate table ARC4 call count cpu elapsed disk query current rows ------- ------ -------- ---------- ---------- ---------- ---------- ---------- Parse 1 0.03 0.02 0 0 1 0 Execute 1 0.83 3663.42 687 2277 2602 0 Fetch 0 0.00 0.00 0 0 0 0 ------- ------ -------- ---------- ---------- ---------- ---------- ---------- total 2 0.86 3663.45 687 2277 2603 0 Misses in library cache during parse: 1 Optimizer mode: ALL_ROWS Parsing user id: 21 (recursive depth: 1) Elapsed times include waiting on following events: Event waited on Times Max. Wait Total Waited ---------------------------------------- Waited ---------- ------------ db file sequential read 689 0.03 1.97 reliable message 9 0.00 0.00 enq: RO - fast object reuse 44 2.94 106.30 local write wait 3868 0.99 3553.96 free buffer waits 8 0.03 0.06
Oracle to perform the truncate, it needs to scan the whole buffer cache checking for any buffers that belong to that object, and dump these dirty buffers on disk, then clean those buffers.
Wait by shadow for DBWR
If the buffer cache is rather “clean”, truncate will likely best delete. If the buffer cache is rather “dirty”, delete might best truncate.
If a problem try
- GTT (global temporary tables)
or
- Reduce fast_start_mttr_targe
Jonathan Lewis
“must sweep all of the blocks in the db_cache_size to remove dirty blocks” is several years out of date. Since 8i, Oracle has had a checkpoint queue which lists all the dirty blocks in order of dirtying. So the work done in clearing dirty blocks should be minimal.
The historic problem with truncate was that Oracle had to “sweep” the cache to find all the CLEAN blocks for an object you were truncating or dropping so that it could mark the buffer-headers as free.
In 10gR2 (as Mladen Gogala will chip in) there is a new mechanism which is supposed to eliminate this requirement. But it seems to have some not so good side effects – which is what your ‘fast object reuse’ wait is about. There is an objectbased linked list running through all the buffer headers for a given object which should make this ‘clean sweep’ efficient – but it looks like it doesn’t work properly.
The “local write wait” is there because when you truncate a table, your session (rather then DBWR) writes the table segment header block, any index segment header blocks, and any index root blocks for that table. The fact that the writes are synchronous in your session’s time (rather than being left to DBWR to write later) make their direct performance impact much more dramatic than normal.
Truncates taking too long …… [ID 334822.1]

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~


对不起,这篇文章暂时关闭评论。