硬件维护存在很高的风险,比如重启、更换硬件、固件升级、驱动升级等操作。通常在进行这些操作前,我会问一句“多久没重启了?” 如果设备多年未重启,那么在重启过程中可能会因为放电和重新加电的过程发现一些硬件损坏,这会导致计划外的启动失败风险,增加停机时间。
前几天,一位朋友的Oracle RAC 2-nodes(Linux 6物理主机,HPE)系统计划进行HBA固件升级。幸运的是,他们采用了滚动节点的升级方式。在节点1升级FC HBA固件(Firmware version)并重启后,CRS启动失败,所有ASM DISK丢失,且在重启时遇到了操作系统无法启动的惊险情况。这里,我分享一下处理这种问题的经验。
通过分享这个案例,希望大家在进行硬件维护时能够更谨慎,提前做好风险评估和应急预案,以减少潜在的故障风险和停机时间。
问题1 共享磁盘消失
节点1重启后,CRS启动失败,检查是ASM规划的共享磁盘全部消失,使用了多路径mutilpath,可以先使用lsblk、fdisk检查设备是否在OS层识别,如果OS层都不显示,也不用关注多路径软件。检查端口是否启用。检查scsi_host和fc_host下的状态,这里使用的是fc.
cat /sys/class/fc_host/[hostsN]/port_state
端口未启动,这里启动端口,磁盘未认到,对于scsi_host可以利用scan文件实现在线设备的重扫描,但是fc_host似乎没有更好的方法,下一步建议重启操作系统。
ILO 检查FC HBA 版本2.02.05 status “Unknown”
问题2 udevd worker unexpectedly returned with status 0x0100
重启后控制台hang住,提示udev 线程hang。输出如下:
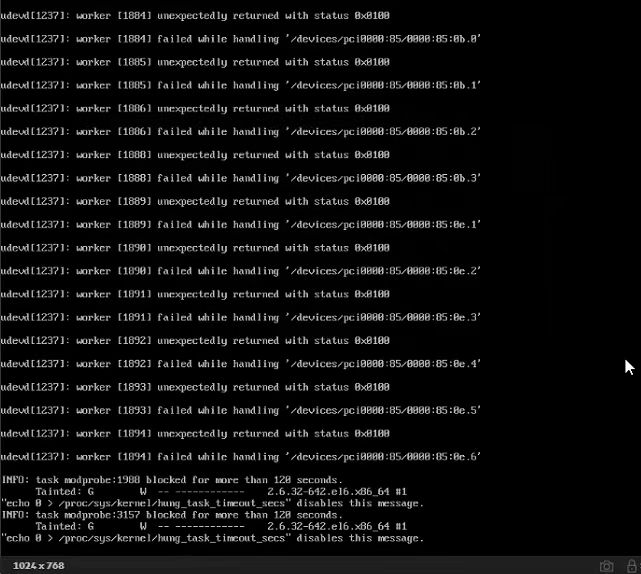
这在RHEL官方有记录是已知问题udevd worker unexpectedly returned with status 0x0100
- A host was losing paths to storage which is configured using device mapper multipath and as they came back, a lot of following errors occurred:
udevd[11136]: worker [13191] failed while handling '/devices/pci0000:00/0000:00:03.2/0000:04:00.1/host2/rport-2:0-4/target2:0:2/2:0:2:31/scsi_device/2:0:2:31' udevd[11136]: worker [13192] unexpectedly returned with status 0x0100 udevd[11136]: worker [13193] failed while handling '/devices/pci0000:00/0000:00:03.2/0000:04:00.1/host2/rport-2:0-5/target2:0:3/2:0:3:32/block/sdvv' udevd[11136]: worker [13204] unexpectedly returned with status 0x0100
- When rebooting a system, error similar to the ones above are experienced
- Rebooting RHEL 6 system after patch, the system fails to boot and boot hangs with udev errors
- My RHEL 6 server sometime hang/kernel panic/reboot with
udeverror message:udevd worker unexpectedly returned with status 0x0100.
根本原因
udev worker 数量取决于系统内存大小,当系统内存和设备数量较多时,可能会出现大量的 worker,由于硬件瓶颈,导致大量进程无法完成,造成 timeout,最终导致 udev 服务失败,甚至系统启动挂起。算是udev bug 1281469 、 1281467.
解决方法
增加更多的kernel options log_buf_len=4M or bigger
升级udev version( udev, libudev 、libgudev1) 到 147-2.63.el6_7.1或以后
或配置CRUB参数临时制定udev进程数udevchilds=128或更小如64, 过多的udevchilds会加重该问题。
另外HPE官方也有记录该案例 Red Hat Enterprise Linux 6 – Boot Hang With Error “udevd[xyz]: worker [xyz] unexpectedly returned with status 0x0100”, 现象是shutdown -r 、reboot会udev报错,但是关闭电源方式关机启动,可以正常启动。
解决也是建议 udevchilds=64 udevtimeout=600 加到/boot/grub/grub.conf 文件中.
这里调整完成重启,问题依旧,开始尝试进单用户模式。
问题3 进单用户或救援模式失败
启动倒计时 按”e”, 进到GRUB 界面继续按”e”, 下一界面选 kernel /vmlinuxz-xxxx的记录,再按”e”, 下面就是提示输入”1″ 或”S”或 “single”, 此时正常会回到上一界面,再按”b” 此时正常可以使用OS的内核驱动去引导进入单用户模式。 文档CentOS6.6 如何进入单用户模式和Linux系统进入救援模式有截图
但是boot仍没有引导进单用户模式,甚至把CRUB boot配置ro quiet行增加了”single” 也无法进入单用户模式。 然后挂载同版本OS ISO 光盘引导,进入救援模式,依旧挂起。 无法进入的报错是在控制台输出到”waiting for hardware to initialize”
问题4 引导启动失败”waiting for hardware to initialize”
到这一步hang应该是硬件在初始化,但是也未告知是哪个硬件,期间尝试拔出FC HBA卡依旧,并且排除所有外设问题依旧,RHEL “Installation hangs at “waiting for hardware to initialize” and then results in a backtrace“现象不太一致, 现在是光盘引导都失败意味着和OS已经没关系了,连操作系统都无法重装。
此时同事建议找个RHEL 7的光盘引导试试,果然LINUX 7可以正常引导,并且能认到所有的ASM 共享存储, 此时问题就明确了,固件升级的是一个2023年的版本后,但是OS启动时光盘中自带的驱动和现有的OS内核引导/boot/vmlinuz-2.6.32-642.el6.x86_64 中的驱动,都无法识别新的固件,所以会导致启动一直在等初始化硬件。
最终通过回滚固件版本,重启恢复正常,避免了一次Oracle RAC的增减节点操作。