Linux多路经DM multipathd for ORACLE RAC ASM注意事项
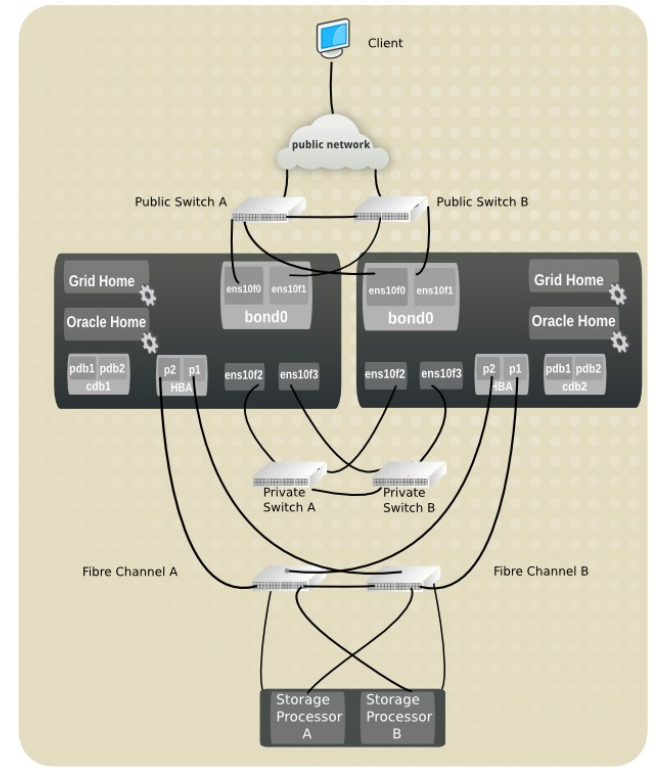
对于服务器与存储分离的数据库环境中,业务数据存储在外挂存储设备上,常见于之前的oracle RAC等集中式数据库,同样也可以用于达梦或mysql数据库,服务器与存储连接常用的有基于NSF的NAS存储和基于Fabric协议的SAN存储,而企业中对于数据库常使用SAN存储,需要专业硬件如HBA卡和SAN交换机。进一步为了高可用一般是多条路径的方式。而Linux RAC环境可以使用存储厂家的多路径软件,也可以使用DM Multipath软件,或使用ASM 的failgroup特性。
对于multipath环境,遇到过几个客户配置了4条链路甚至6条,因为部分链路offline,没有failover链路,导致数据库一样会出现I/O失败现象。这里简单整理几个multipath相关的配置参数。
配置文件 /etc/multipath.conf中default { }有多个参数会影响错误检测和故障转移时间
defaults {
user_friendly_names yes
polling_interval 5
fast_io_fail_tmo 5
dev_loss_tmo 10
checker_timeout 15
max_polling_interval 4
no_path_retry fail
}
-- 调整参数后 reload multipathd 服务
# service multipathd reload
有多个参数会影响错误检测和故障转移时间
polling_interval 指定两次路径检查之间的时间间隔,以秒为单位,缺省值为5。对于功能正常的路径,polling_interval表示最小轮询间隔,路径检查之间的实际时间最多间隔逐渐增加到max_polling_interval。检测到健康路径后,有效轮询间隔将加倍。在RHEL 5和RHEL 6中,翻倍的上限是指定值的4倍。这意味着在两次成功检查之后,轮询间隔是原始时间的4倍。在RHEL 7中,可以使用multipath.conf选项“max_polling_interval”将最大值设置为您想要的任何值。在这种情况下,默认值也是4 * polling_interval。
例如,polling_interval当前默认设置为5。如果以非常冗长的方式启动multipathd守护进程,很容易观察到,健康路径上的路径检查很快就会变成每20秒一次的模式。如果为polling_interval设置了自定义配置值10,那么检查的间隔最终将降至40秒,依此类推。这背后的理由是,确实没有理由如此频繁地检查未失败的路径。路径故障应该是非常罕见的.
max_polling_interval 指定两次路径检查之间的最大时间间隔,以秒为单位。默认值是 4 * polling_interval.
fast_io_fail_tmo SCSI层在一个FC远程端口上检测到问题后,在对该远程端口上的设备进行I/O失败之前等待的秒数。该值必须小于dev_loss_tmo的值。将此设置为off将禁用超时。缺省值为5。 fast_io_fail_tmo选项覆盖底层路径设备的recovery_tmo和replacement_timeout选项的值。影响处于阻塞状态时io排队和保持的时间
dev_loss_tmo 在一个FC远程端口上检测到问题后,SCSI层在从系统中删除该端口之前等待的秒数。将其设置为无穷大将会将其设置为2147483647秒,或68年。默认值由操作系统决定。影响扩展链接超时,在驱动程序放弃等待端口返回之前,在链路断开事件发生后的几秒钟内保持in-flight I/O。默认值是30-35秒,因此in-flight的I/O可以在被终止之前保持几秒钟。超时过期后,报告将处于离线(down)状态。
checker_timeout 用于发出带有显式超时的SCSI命令的优先级排序器和路径检查器的超时,以秒为单位。“sys/block/sd<x>/device/timeout”目录中包含默认值。
no_path_retry 指定在禁用排队之前重试的次数,或者立即失败(没有排队)的失败次数,以及从不停止排队的排队次数。默认配置项为fail。然而,devices{}节将否决这一点。
ASM hangs when One Disk from the Fail-Group Goes Down (Doc ID 2292847.1)
When “no_path_retry” is set to queue, IO to the failed disk is queued forever without returning error. ASM just thinks that disk is still online and keeps sending the IO to the same disk. It doesn’t fail-over to the mirror disk. Set optimum value for “no_path_retry”. Setting no_path_retry to fail will result in immediate IO failure. This may be bad in case of any false-positive failure. A value of 10 is recommended here. The disk will be available for <no_path_retry> * <polling_interval> seconds. Value of polling_interval is 5 seconds by default.
常用命令
# modprobe -l | grep dm-multi # lsmod | grep dm # fdisk -l # ls -la /dev/disk/by-path/ # lsscsi -i # multipath -ll # udevadm info --query=all --name=/dev/sdX | egrep "WWN|SERIAL" $ udevadm info --query=all --name=/dev/mapper/mpathX | grep -i "DM_UUID" # for f in /sys/class/fc_remote_ports/rport-*/fast_io_fail_tmo; do d=$(dirname $f); echo $(basename $d):$(cat $d/node_name):$(cat $f); done rport-8:0-0:0x50014380113622b0:off rport-8:0-1:0x50014380113622b0:off rport-8:0-2:0x50014380113622b0:off rport-8:0-3:0x50014380113622b0:off # for f in /sys/class/fc_remote_ports/rport-*/dev_loss_tmo; do d=$(dirname $f); echo $(basename $d):$(cat $d/node_name):$(cat $f); done rport-8:0-0:0x50014380113622b0:30 rport-8:0-1:0x50014380113622b0:30 rport-8:0-2:0x50014380113622b0:30 rport-8:0-3:0x50014380113622b0:30
用于Oracle RAC时,在Linux 6.2之后配置multipath配置文件里去掉uid,gid,mode这三个参数,需要使用udev修改mutlpath设备的权限
-- 12-dm-permissions.rules
ENV{DM_NAME}=="disk30001",NAME="asmdisk30001", OWNER:="grid", GROUP:="asmadmin", MODE:="660"
ENV{DM_NAME}=="disk30002",NAME="asmdisk30002", OWNER:="grid", GROUP:="asmadmin", MODE:="660"
ENV{DM_NAME}=="disk30003",NAME="asmdisk30003", OWNER:="grid", GROUP:="asmadmin", MODE:="660"
由于在RHEL6.7中引入了Kernel bug(1163769)。 当执行 OS命令service multipathd reload” 或者类似” kpartx -a /dev/mapper/asm1时。会短暂地将block设备的queue limits设置为默认值。 而ASMLib会 不断读取这个值,当发现这个值改变时,会将IO fail,从而 引发DB Crash。
All devices not related to multipath must be put onto the blacklist in /etc/multipath.conf.
blacklist {
devnode "^(ram|raw|loop|fd|md|dm-|sr|scd|st)[0-9]*"
devnode "^hd[a-z]"
devnode "^cciss!c[0-9]d[0-9]*[p[0-9]*]"
}
识别设备
每个多路径设备都有一个全球标识符 (WWID),该标识符保证全局唯一且不变。默认情况下,多路径设备的名称设置为其 WWID。或者,您可以在多路径配置文件中设置 user_friendly_names 选项,设备映射器多路径作为 Linux 本机多路径工具,在 /dev/mapper 下为连接到系统的每个 LUN 创建一个块设备,其节点唯一名称格式为 mpathN。
display a table with disk name and WWID:
#!/bin/ksh for disk in `ls /dev/sd*` do disk_short=`basename $disk` wwid=`scsi_id -g -s /block/$disk_short` if [ "$wwid" != "" ] then echo -e "Disk:" $disk_short "\tWWID:" $wwid fi done
创建 udev 规则
-- 52-oracle.rules'
ACTION==“add|change”, ENV{DM_NAME}==“mpathb”, OWNER=“grid”, GROUP=“asmadmin”, MODE=“0660”
-- 96-storage-asm.rules
ACTION=="add|change", ENV{DM_UUID}=="{dm-uuid-from-udevadm}", SYMLINK+="oracleasm/{asm-disk-name}", GROUP="dba", OWNER="oracle", MODE="0660
for example, using the information from step 1 to create ASM disk named asm01:
ACTION=="add|change", ENV{DM_UUID}=="mpath-36001405a02467a627a24e62afa3d506c", SYMLINK+="oracleasm/asm01", GROUP="dba", OWNER="oracle", MODE="0660"
它们中的任何一个都有效,因为 DM_NAME 和 DM_UUID 在服务器上都是唯一的,可用于唯一标识同一设备,但不要同时使用它们,尽管它无害。
重新加载 udev 规则
# udevadm control --reload-rules # udevadm trigger --type=devices --action=change
References
https://access.redhat.com/solutions/137073
https://access.redhat.com/solutions/16141
https://access.redhat.com/solutions/272153

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~


对不起,这篇文章暂时关闭评论。