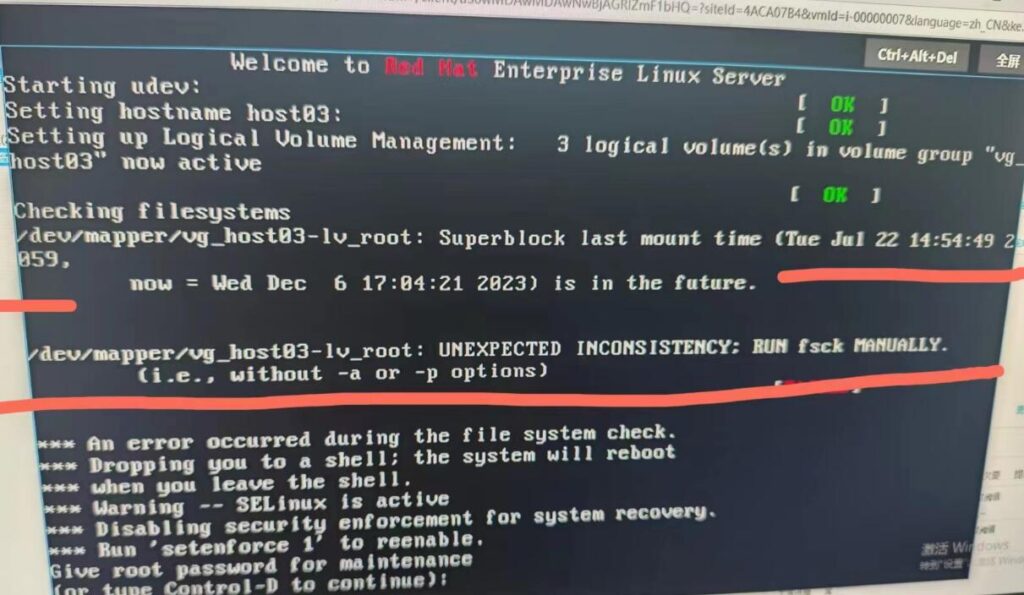
Linux 重启失败Superblock(SB) last mount time is in the future
最近一套华为虚拟化环境中的虚拟主机RHEL linux 6.N 操作系统,调整了memory资源后做reboot重启失败,检查控制台输出提示一个文件系统Superblock last mount time is in the future是2059年,但当前时间是2023年,可能还并不是类似cmos电池问题,重置时间为1988年等之前的时间。启动界面提示要做fsck 手动修复,这里简单记录一下。
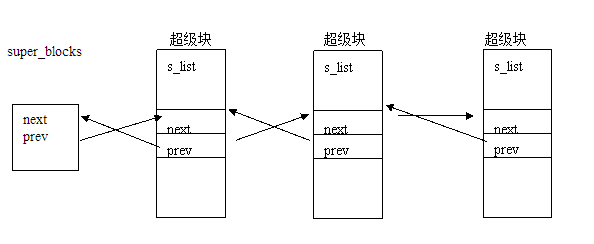
什么是Superblock
super block:记录文件系统的整体信息,包括inode/block 的总量、使用量、剩余量,以及文件系统的格式与相关信息等。默认在设备的0位置开始,分段的连接双向U形结构体,我理解它有点像oracle ASM AU #0
如何查看Superblock信息
Linux 系统命令 dumpe2fs 和 mke2fs 命令可以让我们了解superblock, dumpe2fs是在已mount的文件系统可以打钱supperblock信息, mke2fs -n是一种不真实创建模拟的方式显示,同时对于ext4和XFS文件系统还有不同的区别。
EXT4文件系统
[root@anbob_com ~]# df -T
Filesystem Type 1K-blocks Used Available Use% Mounted on
/dev/mapper/vg_template-lvroot
ext4 73671904 46337524 23585312 67% /
tmpfs tmpfs 8166716 211364 7955352 3% /dev/shm
/dev/sda1 ext4 487652 41368 420684 9% /boot
/dev/sr0 iso9660 3787224 3787224 0 100% /mnt/cdrom
[root@anbob_com ~]# dumpe2fs -h /dev/mapper/vg_template-lvroot
dumpe2fs 1.41.12 (17-May-2010)
Filesystem volume name:
Last mounted on: /
Filesystem UUID: e27471da-f4e8-422b-8f71-8ae374b37ee6
Filesystem magic number: 0xEF53
Filesystem revision #: 1 (dynamic)
Filesystem features: has_journal ext_attr resize_inode dir_index filetype needs_recovery extent flex_bg sparse_super large_file huge_file uninit_bg dir_nlink extra_isize
Filesystem flags: signed_directory_hash
Default mount options: user_xattr acl
Filesystem state: clean
Errors behavior: Continue
Filesystem OS type: Linux
Inode count: 4694016
Block count: 18745344
Reserved block count: 937267
Free blocks: 12457450
Free inodes: 3729069
First block: 0
Block size: 4096
Fragment size: 4096
Reserved GDT blocks: 1019
Blocks per group: 32768
Fragments per group: 32768
Inodes per group: 8192
Inode blocks per group: 512
Flex block group size: 16
Filesystem created: Fri Apr 24 02:42:21 2020
Last mount time: Thu Dec 1 21:32:09 2022
Last write time: Fri Apr 24 02:47:55 2020
Mount count: 10
Maximum mount count: -1
Last checked: Fri Apr 24 02:42:21 2020
Check interval: 0 ()
Lifetime writes: 19 GB
Reserved blocks uid: 0 (user root)
Reserved blocks gid: 0 (group root)
First inode: 11
Inode size: 256
Required extra isize: 28
Desired extra isize: 28
Journal inode: 8
Default directory hash: half_md4
Directory Hash Seed: 69085712-bd1e-4627-84db-cdca3df2773c
Journal backup: inode blocks
Journal features: journal_incompat_revoke
Journal size: 128M
Journal length: 32768
Journal sequence: 0x010c2f1c
Journal start: 10880
[root@anbob_com ~]# dumpe2fs -h /dev/mapper/vg_template-lvroot| egrep "created|time"
dumpe2fs 1.41.12 (17-May-2010)
Filesystem created: Fri Apr 24 02:42:21 2020
Last mount time: Thu Dec 1 21:32:09 2022
Last write time: Fri Apr 24 02:47:55 2020
Lifetime writes: 19 GB
[root@anbob_com ~]# dumpe2fs /dev/mapper/vg_template-lvroot | grep -i superblock
dumpe2fs 1.41.12 (17-May-2010)
Primary superblock at 0, Group descriptors at 1-5
Backup superblock at 32768, Group descriptors at 32769-32773
Backup superblock at 98304, Group descriptors at 98305-98309
Backup superblock at 163840, Group descriptors at 163841-163845
Backup superblock at 229376, Group descriptors at 229377-229381
Backup superblock at 294912, Group descriptors at 294913-294917
Backup superblock at 819200, Group descriptors at 819201-819205
Backup superblock at 884736, Group descriptors at 884737-884741
Backup superblock at 1605632, Group descriptors at 1605633-1605637
Backup superblock at 2654208, Group descriptors at 2654209-2654213
Backup superblock at 4096000, Group descriptors at 4096001-4096005
Backup superblock at 7962624, Group descriptors at 7962625-7962629
Backup superblock at 11239424, Group descriptors at 11239425-11239429
mke2fs -n /dev/mapper/VolGroup01-VolLV01
mke2fs :此命令应在未挂载的文件系统上运行。注意:不要在没有 -n 选项的情况下运行此命令。
# mke2fs -n /dev/mapper/VolGroup01-VolLV01
mke2fs 1.41.12 (17-May-2010)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
1245184 inodes, 4980736 blocks
249036 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=4294967296
152 block groups
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000
XFS文件系统
root@19c1:/root $df -T
Filesystem Type 1K-blocks Used Available Use% Mounted on
devtmpfs devtmpfs 8203412 0 8203412 0% /dev
tmpfs tmpfs 8215380 864764 7350616 11% /dev/shm
tmpfs tmpfs 8215380 894380 7321000 11% /run
tmpfs tmpfs 8215380 0 8215380 0% /sys/fs/cgroup
/dev/mapper/rhel-root xfs 99561988 61294796 38267192 62% /
/dev/sr0 iso9660 4420474 4420474 0 100% /mnt
/dev/sda1 xfs 1038336 139888 898448 14% /boot
tmpfs tmpfs 1643080 0 1643080 0% /run/user/10002
tmpfs tmpfs 1643080 0 1643080 0% /run/user/0
tmpfs tmpfs 1643080 0 1643080 0% /run/user/10001
root@19c1:/root $ dumpe2fs /dev/mapper/rhel-root
dumpe2fs 1.42.9 (28-Dec-2013)
dumpe2fs: Bad magic number in super-block while trying to open /dev/mapper/rhel-root
Couldn't find valid filesystem superblock.
root@19c1:/root $dd if=/dev/mapper/rhel-root bs=512 count=1|strings
1+0 records in
1+0 records out
512 bytes (512 B) copied, 4.7846e-05 s, 10.7 MB/s
XFSB
如果它显示输出,如 XFSB和标签名称,那么我们的主超级块是有效的。
如何修复Superblock
使用fsck或e2fsck可以对EXT4文件系统的supperblock恢复,对于XFS可以使用xfs_repair。
EXT文件系统
# fsck /dev/mapper/vg_host03-lv_root -- 然后一路yes
超级块在文件系统的不同位置保存了多个副本。我们可以使用这些副本在文件系统上运行 e2fsck 或挂载文件系统。我们无法在 0 位置的超级块上运行文件系统检查。因此,我们继续对位于 32768 的超级块进行文件系统检查(取自 Step1 输出的值)。 使用e2fsck是不可以在已mount的文件系统上.
[root@anbob_com ~]# e2fsck -b 32768 /dev/mapper/vg_template-lvroot e2fsck 1.41.12 (17-May-2010) /dev/mapper/vg_template-lvroot is mounted. e2fsck: Cannot continue, aborting. [root@node1 ~]# e2fsck -b 32768 /dev/mapper/VolGroup01-VolLV01 e2fsck 1.41.12 (17-May-2010) One or more block group descriptor checksums are invalid. Fix? yes Group descriptor 0 checksum is invalid. FIXED. Group descriptor 1 checksum is invalid. FIXED. Group descriptor 2 checksum is invalid. FIXED. ...
使用另一个 superblock 副本挂载文件系统
由于我们无法使用从 0 开始的默认超级块挂载文件系统。我们将尝试挂载 superblock 的文件系统副本。
[root@node1 ~]# mount -o sb=98304 /dev/mapper/VolGroup01-VolLV01 /var/crash1
XFS文件系统
*如果以防万一,我们无法看到上述输出,那么我们必须使用备用超级块选项进行修复。 # xfs_repair -vL /dev/sdc
解决方法
我们是因为superblock记录的mount时间是个未来时间,只是因为时间不一致,还不至于导致文件系统损坏或数据丢失,注意不要在维护模式尝试挂载文件系统继续使用,使用runleve命令可以查看启动级别,如果是维护模式显示是”unknow”, 而一般正常是3或5。同时维护模式使用lsblk -f 也不显示文件系统,此时如果启动listener会提示当前文件系统为只读,
解决方法有2种:
1,进入维护模式,使用date命令修改系统时间,到mount的修改时间之后,如这里是2059年,重启可以正常进入文件系统,需要修改会正常时间在再启动应用如listener或db instance, 但是注意下次重启大概率还会导致SB与当前时间不一致问题,导致OS无法正常启动,建议使用方法2#
2,进入维护模式,运行fsck 修复supperblock中的mount时间,重启。
— 2023-12-29 update —
最近同事遇到了一个ORACLE ACFS superblock 损坏的问题, 发现fsck同样支持ACFS文件系统, How to use FSCK to check and repair ACFS. (Doc ID 1644499.1)
/bin/mount -t acfs /dev/asm/rman-120 /rman
mount: wrong fs type, bad option, bad superblock on /dev/asm/rman-120,
missing codepage or helper program, or other error
In some cases useful info is found in syslog - try
dmesg | tail or so
mount.acfs: CLSU-00100: Operating System function: mount failed with error data: 22
mount.acfs: CLSU-00101: Operating System error message: Invalid argument
mount.acfs: CLSU-00103: error location: MOUNT_3
mount.acfs: ACFS-02126: Volume /dev/asm/rman-120 cannot be mounted.
解决方法
修复文件系统for linux
# fsck -t acfs /dev/asm/rman-120

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~


对不起,这篇文章暂时关闭评论。