How to speed up create index on Oracle and PostgreSQL(加速索引创建)?
创建索引是table优化访问的常用手段, 但是通常create index会影响对表上的其他DML执行(非online), oracle和postgresql在该方面提供了online的方法,但是可能会增加索引的创建时间,对于表大小超过GB创建索引你可能希望如何加速创建索引,回想几年前某运营商没有使用online创建索引导致业务堵塞几十分钟,刚好找我协助解决,从创建进度估算可能还要很久,取消之前的操作,一堆猛操作分分钟同样创建完了索引,赢得了认可。因为mysql通常用于小型业务,但Oracle和PostGreSQL则不乏有TB级数据库,如何利用现有资源加速索引创建? 思路基本相同最大化I/O,内存区,并行等。
On Oracle
创建索引前session级修改
alter session set workarea_size_policy=MANUAL; alter session set db_file_multiblock_read_count=512; alter session set events '10351 trace name context forever, level 128'; alter session set sort_area_size=734003200; alter session set "_sort_multiblock_read_count"=128; alter session enable parallel ddl; alter session set db_file_multiblock_read_count=512; alter session set db_file_multiblock_read_count=512; alter session set "_sort_multiblock_read_count"=128; alter session set "_sort_multiblock_read_count"=128; create index xxx on xxx(xxx) parallel xxx; -- 对于多个分区,如优先创建最新分区 create index xx on xx(xxx) local unusable; alter index xxx rebuild partition xxx; -- 对于业务要求不间断,Online创建索引 crate index xxx on xxx(xxx) Online local parallel nologging;
On PostgreSQL
— 优化平行参数
weejar=#set max_parallel_maintenance_workers=8; -- default 2 weejar=# show max_parallel_workers; max_parallel_workers ---------------------- 8 weejar=# show max_worker_processes; max_worker_processes ---------------------- 8
请注意,并行工作器取自max_worker_processes建立的流程池,受max_parallel_workers限制,请求的工作器数量在运行时可能实际上不可用。
— 优化内存参数
weejar=# set maintenance_work_mem to '2000 MB'; --default 64MB
在一些postgresql中最大2GB, 但在Openguass或之前一些版本可以配置正大值, 如opengauss 3.1
anbob=# set maintenance_work_mem to '4 GB'; SET anbob=# show maintenance_work_mem; maintenance_work_mem ---------------------- 4GB (1 row)
— 增加checkpoint的间隔
set checkpoint_time='120min' set max_wal_size=50GB; set min_wal_size=80mb; ALTER SYSTEM SET shared_buffers TO '64 GB'; select pg_reload_conf();
max_wal_size: 这控制检查点之间的距离和 WAL 的大小。它对减少 I/O 量和加快 I/O 速度有很大帮助。
max_parallel_maintenance_workers: 此变量控制允许 PostgreSQL 启动多少个工作进程来构建索引。它定义了 worker 的上限。
maintenance_work_mem: 这定义了每个操作在内存中可以发生多少。
shared_buffers:I/O 高速缓存的大小
如果 VACUUM 操作需要很长时间,这可以让我们了解数据库内部发生的事情:
# VACUUM ANALYZE; VACUUM Time: 91293.971 ms (01:31.294 # SELECT * FROM pg_stat_progress_vacuum;
— 利用更多的硬盘
create tablespace tbs_ind location '/ssd1/tbsind01'; create tablespace tbs_sort location '/ssd2/tbssort01'; set temp_tablespace to tbs_sort; create index xx on xx(xxx) tablespace tbs_ind;
有趣的是 PostgreSQL 在创建索引时做了什么。我们可以检查系统视图以提供一些线索:
SELECT * FROM pg_stat_progress_create_index;
— 不轻易使用CONCURRENTLY
创建索引时可以增加CONCURRENTLY选项,以不阻塞DML的方式创建索引(加ShareUpdateExclusiveLock锁),
需要执行先后两次对该表的全表扫描来完成build,第一次扫描的时候创建索引,不阻塞读写操作;第二次扫描的时候合并更新第一次扫描到目前为止发生的变更。由于需要执行两次对表的扫描和build,而且必须等待现有的所有可能对该表执行修改的事务结束。这意味着该索引的创建比正常耗时更长
— 适用更适合的列数据类型
如用int4 代替 numberic;
Table 8.2. Numeric Types
| Name | Storage Size | Description | Range |
|---|---|---|---|
smallint |
2 bytes | small-range integer | -32768 to +32767 |
integer |
4 bytes | typical choice for integer | -2147483648 to +2147483647 |
bigint |
8 bytes | large-range integer | -9223372036854775808 to +9223372036854775807 |
decimal |
variable | user-specified precision, exact | up to 131072 digits before the decimal point; up to 16383 digits after the decimal point |
numeric |
variable | user-specified precision, exact | up to 131072 digits before the decimal point; up to 16383 digits after the decimal point |
real |
4 bytes | variable-precision, inexact | 6 decimal digits precision |
double precision |
8 bytes | variable-precision, inexact | 15 decimal digits precision |
smallserial |
2 bytes | small autoincrementing integer | 1 to 32767 |
serial |
4 bytes | autoincrementing integer | 1 to 2147483647 |
bigserial |
8 bytes | large autoincrementing integer | 1 to 9223372036854775807 |
CYBERTEC 曾做过一个测试
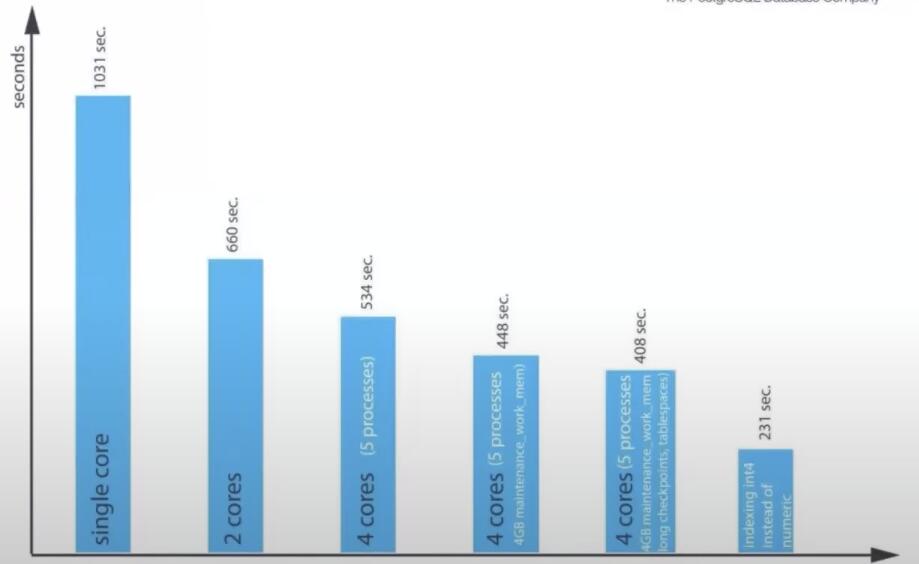
— enjoy —

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~


对不起,这篇文章暂时关闭评论。