Linux最佳实践for Postgresql/openGauss
Linux 内核提供了各种可能影响性能的配置选项,为了获得最佳性能,PostgreSQL 数据库取决于正确定义的操作系统参数。操作系统内核参数配置不当可能会导致数据库服务器性能下降与系统稳定。因此,必须根据数据库服务器及其工作负载配置这些参数。就像任何其他数据库一样,PostgreSQL依赖于Linux内核进行最佳配置。在这篇文章中,我们将讨论一些可能影响数据库服务器性能的重要 Linux 内核参数以及如何调整这些参数。 因此,在每次优化会话之后对数据库性能进行基准测试以避免性能下降非常重要。
–提示:仅供参考
禁用SElinux
在Oracle、MySQL中同样也建议关闭SELinux功能,PostgreSQL中同样建议禁用。该参数通常有3个值:enabled、disabled、Permissive。如果有安全要求不允许禁用,可以尝试调为宽容模式Permissive。
关闭数据库主机的安全加固(SELinux)方式如下:
将/etc/selinux/config文件中的SELINUX=enabled修改为SELINUX=disabled,该修改重启主机生效。
#vi /etc/sysconfig/selinux 验证方式: 命令 # cat /etc/selinux/config|grep ^SELINUX= 打印结果为:SELINUX=disabled
禁用OS 防火墙
建议禁用操作系统iptables和firewall服务
Stop the iptables ============= #service stop iptables # chkconfig iptables off Stop the firewall ============= #systemctl status firewalld #systemctl stop firewalld #systemctl disable firewalld
RAID配置
RAID配置可以提供冗余与条带(除了RAID 0)这重要在数据库服务器上通常都会配置,当然也有一些分布式存储在软件定义层实现了多副本,可以不做RAID。RAID不能消除备份的需求,恢复时间取决于控制器、RAID等级、阵列大小与硬盘速度 ,相同时间损坏多块盘是有可能的,尤其是使用SSD。 通常是建议RAID 10级别为数据库提供较好的读写性能与安全,但是缺点是昂贵或热点数据在一对磁盘上,次要的折中是RAID 5,允许1块盘失效,随机写昂贵每次随机写要2次读与2次写 计算和存储校验位,顺序写好些,所以可以放日志或读为主的业务,1块盘失效时重组也会更久。
另外缓存策略writethrough(nocache)与writeBack(cache)与raid条带块大小、缓存预读也影响IO性能, Troubleshooting Oracle redo file on SSD wait event ‘log file sync’ 案例在Oracle on SSD时Writethrough, ReadAheadNone, Direct, nocache.有比较好的性能, 而PG对于缓存预读中获益也可能极小,而是利用数据库自己的预读功能,RAID预读还可能干扰重要的CACHE与同步写入操作,因为RAID的cache相对于数据库太小了,但是对于I/O合并写 WriteBack理论上可以收益。
记的部署监控raid失效盘与RAID控制器电池放电时间。
文件系统
从因为postgresql、mysql是数据通常在文件系统中,而不是像Oracle可以使用ASM(direct nocache I/O)上已做优化, 对于数据库的安全要注当前通常使用ext4和xfs为主流文件系统,
在平均文件较小,并发较小的IO场景,ext4和xfs表现差不多,前者略微胜出。
当文件较大,并发较大时,xfs比ext4性能更好,同时更稳定。
实际使用上来说,一般数据库的文件系统推荐用xfs(但OS上的恢复比较麻烦)
文件访问时间调整
每次在 Linux 中访问文件时,都会更新一个称为文件上次访问时间 (atime) 的文件属性。您可以通过将 noatime 添加到 /etc/fstab 中的卷装入选项来在数据库卷上禁用此功能。请注意,设置 noatime 会禁用访问时间的 nodiratime 和相对时间级别
/dev/sda1 /pgsql ext4 noatime,errors=remount-ro 0 1
写入屏障(Write Barrier Tuning)调整
当PostgreSQL写入磁盘时,它会执行其中一个系统fsync调用(fsync或fdatasync)以将该数据刷新到磁盘。默认情况下,假定硬盘和磁盘控制器上的缓存是易失性的:当电源故障时,写入其中的数据将丢失。由于这可能会导致文件系统和/或数据库损坏,因此 Linux 中的 fsync 会发出写入屏障,将所有数据强制到物理磁盘上。这将刷新 RAID 和驱动器写缓存上的写缓存。
当数据库硬件包含正确设置的电池备份写入时,这不是必需的。对该缓存的写入不是易失性的;在电源中断的情况下,它们将被保存。在这种情况下,您可以关闭该磁盘上的屏障。这可显著提高写入性能。您可以通过在 /etc/fstab 中的卷装入选项中添加 nobarrier 来禁用数据库卷上的屏障。
/dev/sda1 /pgsql ext4 noatime,nobarrier,errors=remount-ro 0 1
如果把RAID 条带、文件系统、VG块大小与数据库块大小对齐有可能会有10%的性能提升,但是理想状态配置较为困难,当前的SSD对这类IO应该影响不大。
Note:
需要考虑后期文件系统空间扩容,所以可以考虑使用VG,方便扩容。
磁盘调度算法
磁盘调度算法默认是使用的CFQ算法,对于数据库专用服务器,如果为机械磁盘,建议将磁盘调度算法调整为deadline模式,如果为固态硬盘SSD,调整为noop模式或None,以提升I/O吞吐量和降低I/O响应时间。
采用如下方式进行调整:
echo “deadline” >/sys/block/$磁盘名/queue/scheduler
— or —
echo “none” >/sys/block/$磁盘名/queue/scheduler
实际效果可以使用fio 压测。
磁盘队列深度nr_requests 和 queue_depth
操作系统中nr_requests参数,可以提高系统的吞吐量,命令: echo xxx > /sys/block//queue/nr_requests,nr_requests的大小设置至少是/sys/block//device/queue_depth的两倍,I/O调度器中的最大I/O操作数是nr_requests * 2。一个磁盘设备的I/O操作的最大未完成限制为(nr_requests * 2)+(queue_depth) 。对应iostat 的avgqu-sz。当对系统进行极限性能测试时,为了增大主机写I/O的压力及I/O在队列中被合并的概率,可以适当的增大此参数。可以通过如下方法临时修改块设备的队列深度。
$ echo “512” > /sys/block/sda/queue/nr_requests IO 请求的IO调度队列大小
$ echo “256” > /sys/block/sda/device/queue_depth 请求在磁盘设备上的队列深度
预读量
Linux的预读功能类似于RAID的预读算法,仅对顺序读有效且会对顺序流进行识别,并提前读取“read_ahead_kb”(单位为扇区)长度的数据。
# cat /sys/block/sdc/queue/read_ahead_kb 当业务需要对大量的大文件进行读取时,可以通过适当调大此参数提升性能。可以通过如下方法修改块设备的预读量。
echo 1024 > /sys/block/sdc/queue/read_ahead_kb
SHMMAX / SHMALL内核参数
SHMMAX 是一个内核参数,用于定义 Linux 进程可以分配的单个共享内存段的最大大小。在版本9.2之前,PostgreSQL使用需要SHMMAX设置的系统V(SysV)。在 9.2 之后,PostgreSQL 切换到 POSIX 共享内存。所以现在它需要更少的SYS-V 共享内存。在9.3版本之前,SHMMAX是最重要的内核参数。SHMMAX 的值以字节为单位。同样,SHMALL 是另一个内核参数,用于定义系统范围的共享内存页总数。要查看 SHMMAX、SHMALL 或 SHMMIN 的当前值,请使用 ipcs 命令。
$ ipcs -lm ------ Shared Memory Limits -------- max number of segments = 4096 max seg size (kbytes) = 1073741824 max total shared memory (kbytes) = 17179869184 min seg size (bytes) = 1
PostgreSQL使用System V IPC来分配共享内存。此参数是最重要的内核参数之一。每当您收到以下错误消息时,这意味着您使用的是旧版本的PostgreSQL,并且SHMMAX值非常低。用户应根据要使用的共享内存调整和增加值。
可能的配置错误
如果 SHMMAX 配置错误,则在尝试使用 initdb 命令初始化 PostgreSQL 集群时可能会出错。
initdb Failure
DETAIL: Failed system call was shmget(key=1, size=2072576, 03600). HINT: This error usually means that PostgreSQL's request for a shared memory segment exceeded your kernel's SHMMAX parameter. You can either reduce the request size or reconfigure the kernel with larger SHMMAX. To reduce the request size (currently 2072576 bytes), reduce PostgreSQL's shared memory usage, perhaps by reducing shared_buffers or max_connections. If the request size is already small, it's possible that it is less than your kernel's SHMMIN parameter, in which case raising the request size or reconfiguring SHMMIN is called for. The PostgreSQL documentation contains more information about shared memory configuration. child process exited with exit code 1
同样,使用 pg_ctl 命令启动 PostgreSQL 服务器时,可能会出现错误。
pg_ctl Failure
DETAIL: Failed system call was shmget(key=5432001, size=14385152, 03600). HINT: This error usually means that PostgreSQL's request for a shared memory segment exceeded your kernel's SHMMAX parameter. You can either reduce the request size or reconfigure the kernel with larger SHMMAX.; To reduce the request size (currently 14385152 bytes), reduce PostgreSQL's shared memory usage, perhaps by reducing shared_buffers or max_connections. If the request size is already small, it's possible that it is less than your kernel's SHMMIN parameter, in which case raising the request size or reconfiguring SHMMIN is called for. The PostgreSQL documentation contains more information about shared memory configuration.
sysctl 命令可用于临时更改值。要永久设置该值,请在 /etc/sysctl.conf 中添加一个条目.
Transparent HugePages透明大页
透明 HugePages 处于启用状态,并分配可能不建议用于数据库。对于一般的数据库,需要固定大小的HugePages,而Transparent HugePages不提供。因此,始终建议禁用此功能并默认为经典的HugePages。对于oracle\pg同样适用。
默认情况下,THP通常处于启用状态。使用以下命令检查大页面的当前状态。
# cat /sys/kernel/mm/transparent_hugepage/enabled [always] madvise never
[always]输出中的标志显示系统上启用了 Hugepages。
对于使用HugePages的应用程序,它必须包含明确的指令。以这种方式更改应用程序并不总是可行的,因此还有另一种选择。透明 HugePages 在 Linux 内核中提供了一个层——可能从版本 2.6.38 开始——如果启用该层,可能会为应用程序分配 HugePages,而它们实际上并不“知道”它;因此透明度。预期这将提高应用程序性能。HugePage的分配可能很棘手。虽然传统的HugePages保留在虚拟内存中,但THP不是。在后台,内核尝试分配 THP,如果失败,将默认为标准 4k 页面。这一切都对用户透明地发生。
分配过程可能涉及许多内核进程,其中可能包括 kswapd、碎片整理和 kcompactd。所有这些都负责在虚拟内存中为未来的 THP 腾出空间。需要时,分配由另一个内核进程进行;
这取决于 khugepaged 的配置方式,但由于事先没有保留内存,因此性能可能会下降。每次尝试分配 HugePage 时,可能会调用许多内核进程。它们执行某些操作,以便在虚拟内存中为THP分配腾出足够的空间。尽管没有向应用程序提供通知,但会花费宝贵的资源,这可能会导致性能峰值,任何指示尝试分配 THP 的下降。
解决数据库透明大页面的神话 – Percona 数据库性能博客 基准测试显示 THP确实没有性能提升,并且还有不稳定因素,建议禁用。
可以使用命令行查看当前设置
临时更改
可以使用命令行启用或禁用它。
# echo never > /sys/kernel/mm/transparent_hugepage/enabled
Hugepage普通大页
Hugepage不同于上面的Transparent HugePages,默认情况下,Linux使用4K内存页面,BSD有超级页面,而Windows有大页面。页面是分配给进程的 RAM 块。一个进程可能拥有多个页面,具体取决于其内存要求。进程需要的内存越多,分配给它的页就越多。操作系统维护一个页面分配给进程的表(pagetable)。页面大小越小,表越大,在该页表中查找页面所需的时间就越多。因此,大页面可以在减少开销的情况下使用大量内存;更少的页面查找,更少的页面错误,通过更大的缓冲区进行更快的读/写操作。这样可以提高性能。对于oracle、pg同样适用。
PostgreSQL仅在Linux上支持更大的页面。默认情况下,Linux 使用 4K 的内存页,因此在内存操作过多的情况下,需要设置更大的页面。通过使用大小为 2 MB 和最大 1 GB 的大页面,已观察到性能提升。虽然较小的页面大小对于常规用途很有用,但某些内存密集型应用程序可能会通过使用较大的内存页面来提高性能。通过为它们提供更大的内存块,它们可以减少查找时间并提高读/写操作的性能。
为了能够使用大页面,进程用户必须是 /proc/sys/vm/hugetlb_shm_group 中设置的组的成员
检查当前大页配置:
$ cat /proc/meminfo | grep -i huge AnonHugePages: 0 kB ShmemHugePages: 0 kB HugePages_Total: 0 HugePages_Free: 0 HugePages_Rsvd: 0 HugePages_Surp: 0 Hugepagesize: 2048 kB
在此示例中,尽管大页面大小设置为 2,048 (2 MB),但大页面总数的值为 0。这表示大页面被禁用。
量化大页面的脚本
这是一个简单的脚本,返回所需的大页面数。在 PostgreSQL 运行时在 Linux 机器上执行脚本。确保$PGDATA环境变量设置为PostgreSQL的数据目录。
#!/bin/bash
pid=`head -1 $PGDATA/postmaster.pid`
echo "Pid: $pid"
peak=`grep ^VmPeak /proc/$pid/status | awk '{ print $2 }'`
echo "VmPeak: $peak kB"
hps=`grep ^Hugepagesize /proc/meminfo | awk '{ print $2 }'`
echo "Hugepagesize: $hps kB"
hp=$((peak/hps))
echo Set Huge Pages: $hp
Note: 如果一台机器配置多套PostGreSQL记的要配置总大小的和。
运行下面的脚本以获取系统级当前需要多少大页面。该脚本来自 Oracle。
#!/bin/bash
#
# hugepages_settings.sh
#
# Linux bash script to compute values for the
# recommended HugePages/HugeTLB configuration
#
# Note: This script does calculation for all shared memory
# segments available when the script is run, no matter it
# is an Oracle RDBMS shared memory segment or not.
# Check for the kernel version
KERN=`uname -r | awk -F. '{ printf("%d.%d\n",$1,$2); }'`
# Find out the HugePage size
HPG_SZ=`grep Hugepagesize /proc/meminfo | awk {'print $2'}`
# Start from 1 pages to be on the safe side and guarantee 1 free HugePage
NUM_PG=1
# Cumulative number of pages required to handle the running shared memory segments
for SEG_BYTES in `ipcs -m | awk {'print $5'} | grep "[0-9][0-9]*"`
do
MIN_PG=`echo "$SEG_BYTES/($HPG_SZ*1024)" | bc -q`
if [ $MIN_PG -gt 0 ]; then
NUM_PG=`echo "$NUM_PG+$MIN_PG+1" | bc -q`
fi
done
# Finish with results
case $KERN in
'2.4') HUGETLB_POOL=`echo "$NUM_PG*$HPG_SZ/1024" | bc -q`;
echo "Recommended setting: vm.hugetlb_pool = $HUGETLB_POOL" ;;
'2.6' | '3.8' | '3.10' | '4.1' ) echo "Recommended setting: vm.nr_hugepages = $NUM_PG" ;;
*) echo "Unrecognized kernel version $KERN. Exiting." ;;
esac
# End
您可以将其保存为 然后像下面这样运行它:/tmphugepages_settings.sh
现在在 $PGDATA/postgresql.conf 中将参数设置为 huge_pages “on” 并重新启动服务器。刚启动时可能看到使用了极少数hugepage。现加载数据使用一段后HugePages_Free才会发现减少。
通常,HugePages的大小为1MB、2MB和1GB, 当数据库适合启用了 HugePages 的共享缓冲区时,您将看到最大的性能提升。决定要使用的大页面的大小需要一些试验和错误,但这可能会导致显着的 TPS 增益,其中数据库大小很大,但仍然足够小以适合共享缓冲区。默认hugepage size为2M,如果配置hugepage size到1GB需要配置并重启OS, 对于2MB还是1GB的hugepage size需要反复的基准测试,但是ibrar Ahmed测试1Gb hugepages有较好的TPS提升。
Ibrar Ahmed‘s Benchmark PostgreSQL With Linux HugePages 中更改不同hugepage pagesize大小后的基准数据:
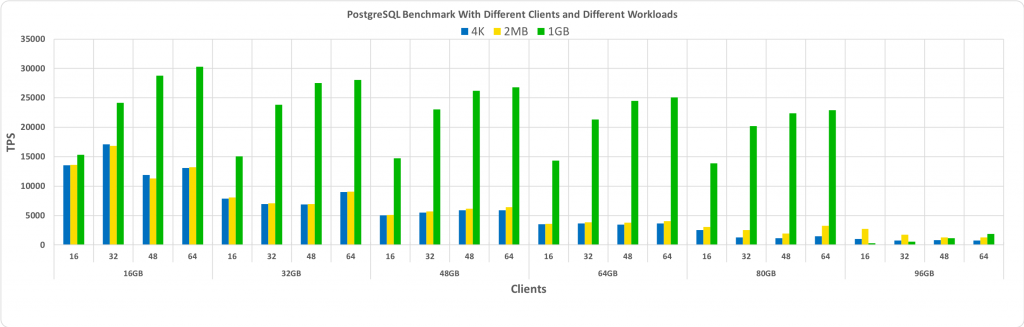
显然,从上图中,您可以看到,只要大小保持在预先分配的共享缓冲区内,HugePages 的性能提升就会随着客户端数量和数据库大小的增加而增加。正如预期的那样,当数据库溢出到预先分配的 HugePages 上时,性能会显着下降。
vm.swappiness
vm.swappiness 是另一个可能影响数据库性能的内核参数。此参数用于控制 Linux 系统上的交换性(将页面与交换内存交换到 RAM)行为。值范围为 0 到 100。它控制将交换或分页的内存量。swapiness是的一个内核参数,目的是用来控制页交换比例的一个阈值,其设置范围为0-100,值越高说明内核使用交换区更加频繁,零表示禁用交换 。该参数在ORACLE\Postgresql同样适用,根据Redhat的性能调整建议:Tuning Red Hat Enterprise Linux for Oracle and Oracle RAC 此文档提到Swapping for Oracle is bad并且建议将vm.swappiness这个参数设置为0。而Oracle Support建议将这个值设置为100,两个意见截然相反, 那到底该听谁的?Red Hat方:主要是站在性能的角度出发的。Oracle方:主要是出于稳定的角度(对于因连接风暴导致内存耗竭而引起的节点驱逐场景)。所以如果内存足够大不是Oracle GI的环境, 您可以通过设置较低的值来获得良好的性能,较小的值是提高PostgreSQL性能的好选择。
在较新的内核中设置值 0 可能会导致 OOM Killer(Linux 中的内存不足终止进程)终止该进程。因此,为了安全起见,如果要最大程度地减少交换,则可以将值设置为 1。Linux 系统上的默认值为 60。较高的值会导致 MMU(内存管理单元)比 RAM 利用更多的交换空间,而较低的值会在内存中保留更多的数据/代码。
vfs_cache_pressure
表示内核回收用于directory和inode cache内存的倾向;缺省值100表示内核将根据pagecache和swapcache,把directory和inode cache保持在一个合理的百分比;降低该值低于100,将导致内核倾向于保留directory和inode cache;增加该值超过100,将导致内核倾向于回收directory和inode cache。 linux 文件系统的cache分为2种page cache Buffers(用于块设备的操作) 和 buffer cache Cached(用于文件,inode等操作), 当发现meminfo或free输出中cached较大时说明是fs cache使用,极端情况下可以优化该参数。把参数vm.vfs_cache_pressure加大到200或500.
vm.overcommit_memory / vm.overcommit_ratio内核参数
Linux 尝试节省内存资源。当您从内核请求内存块时,Linux 不会立即为您保留该内存。您得到的只是一个指针和您可以在目标处使用内存的承诺。内核仅在您实际使用内存时分配内存。这样,如果您请求 1MB 内存,但只使用了其中的一半,则另一半永远不会被分配,并且可用于其他进程(或内核页面缓存)。超售是世界各地航空公司长期以来一直在使用的概念。他们卖的座位比飞机上实际的座位多。内存超额commit的机制就是overcommit_memory。Linux 做同样的事情:它分配(“提交”)比机器中实际可用的内存多,希望不是所有进程都会使用它们分配的所有内存。这种内存超额使用非常适合有效地使用资源,但它有一个问题:如果所有航班乘客都出现,也就是说,如果进程实际使用的内存多于可用内存,该怎么办?
如果一个进程试图使用它已经分配的内存,但内核无法提供它,那么 Linux 只能做一件事:它激活一个叫OOM kill的组件,该组件杀死一个使用大量内存的倒霉进程。
在繁忙的数据库上,如果一个pg的子进程被Kill, postmaster进程为了防止潜在的损坏蔓延,它杀死所有其他数据库连接,进入恢复模式,并修复数据库实例。崩溃恢复可能需要相当长的时间 — PostgreSQL 必须重放自最新检查点以来数据修改写入的所有 WAL。在此期间,您无法连接到数据库。任何连接尝试都将导致错误“数据库系统处于恢复模式”。
禁用 Linux 内存超额使用
禁用内存超额使用时,请务必确保内存当前未超额使用。否则,您的计算机可能会变得不可用。执行grep -i commit /proc/meminfo, 检查 当前CommitLimit和Committed_As参数。
CommitLimit是一个内存分配上限,
CommitLimit = 物理内存 * overcommit_ratio(默认50,即50%) + swap大小 ,如果配置大页committable memory = swap + (RAM – vm.nr_hugepages * huge page size) * vm.overcommit_ratio / 100
Committed_As是已经分配的内存大小。
vm.overcommit_memory文件指定了内核针对内存分配的策略,其值可以是0( default)、1、2,以下是vm.overcommit_memory参数的可能值以及每个参数的说明:
– 0启发式过度提交,智能地执行,基于内核启发式,表示内核将检查是否有足够的可用内存供应用进程使用;如果有足够的可用内存,内存申请允许;否则,内存申请失败,并把错误返回给应用进程。0 即是启发式的overcommitting handle,会尽量减少swap的使用
– 1 无论如何都允许超过CommitLimi使用,表示内核允许分配所有的物理内存,而不管当前的内存状态如何,允许超过CommitLimit,直至内存用完为止。在数据库服务器上不建议设置为1,从而尽量避免使用swap.
-2 拒绝超过CommitLimit的分配。
#define OVERCOMMIT_GUESS 0
#define OVERCOMMIT_ALWAYS 1
#define OVERCOMMIT_NEVER 2参考: https://www.kernel.org/doc/Documentation/vm/overcommit-accounting
vm.overcommit_ratio是可用于过度使用的 RAM 百分比。在具有 2 GB RAM 的系统上,50% 的值最多可以commit 3 GB 的 RAM。这个参数值只有在vm.overcommit_memory=2的情况下,这个参数才会生效。
值 2 表示 vm.overcommit_memory 为 PostgreSQL 带来更好的性能。此值可最大化服务器进程的 RAM 利用率,而不会有任何被 OOM 终止程序进程杀死的重大风险。应用程序将能够过度提交,但只能在过度提交比率内,从而降低 OOM 杀手杀死进程的风险。因此,值为 2 比默认值 0 值提供更好的性能。但是,可以通过确保超出允许范围的内存不会过载来提高可靠性。它避免了进程被 OOM-killer 杀死的风险。
Note: If you set
vm.overcommit_kbytes, it will overridevm.overcommit_ratio.
在没有swap的系统上,当vm.overcommit_memory为 2 时可能会遇到问题。
https://www.postgresql.org/docs/current/static/kernel-resources.html#LINUX-MEMORY-OVERCOMMIT
vm.dirty_background_ratio / vm.dirty_background_bytes
vm.dirty_background_ratio是填充了需要刷新到磁盘的脏页的内存百分比。触发pdflush/flush/kdmflush等后台回写进程运行。此参数的值范围为 0 到 100;但是,小于 5 的值可能无效,并且某些内核内部不支持它。在大多数 Linux 系统上默认值为 10。您可以以较低的比率获得写入密集型操作的性能,这意味着 Linux 会在后台刷新脏页。影响所有全局系统进程。
您需要根据磁盘速度设置 vm.dirty_background_bytes 值。
这两个参数没有“好”值,因为两者都取决于硬件。但是,在大多数情况下,建议将磁盘速度的vm.dirty_background_ratio设置为 5,将vm.dirty_background_bytes设置为 25%,可将性能提高多达 ~25%。或建议vm.dirty_background_bytes=67108864(64 兆字节),您不能同时设置比率 * 和 * 字节。您设置一个或另一个。
vm.dirty_ratio / dirty_bytes
这与vm.dirty_background_ratio / dirty_background_bytes相同,只是刷新是在前台完成的,单个进程的脏页数量达到系统总内存的多大比例后,就会触发pdflush/flush/kdmflush等后台回写进程运行,从而阻止了应用程序。所以vm.dirty_ratio应该高于vm.dirty_background_ratio,当vm.dirty_background_ratio设置为5-10,将vm.dirty_ratio设置为它的两倍左右,以确保能持续将脏数据刷新到磁盘,避免瞬间I/O写,这将确保后台进程在前台进程之前启动,以尽可能避免阻塞应用程序。您可以根据磁盘 IO 负载调整两个比率之间的差异。建议调整vm.dirty_ratio 将此值减少到10,可以使刷新更加频繁,但会减少I/O峰值。或建议vm.dirty_bytes=536870912(512 兆字节),您不能同时设置比率 * 和 * 字节。您设置一个或另一个。
vm.dirty_writeback_centisecs
在需要写入之前,缓存中可以有多长时间。建议30秒。当pdflush/flush/kdmflush进程启动时,它们将检查脏页的年龄,如果它比这个值更老,它将异步写入磁盘。由于在内存中保存脏页面是不安全的,这也是防止数据丢失的一种保护措施。vm.dirty_expire_centisecs = 3000
vm.dirty_expire_centisecs
pdflush/flush/kdmflush进程多久唤醒一次并检查是否需要完成工作。 vm.dirty_writeback_centisecs = 500
禁用C state节能模式
现在的硬件服务器会启用节能模式,或c state, 或CPU 自动调频模式, 当系统负载较空闲时会自动内部调整CPU 睡眠比例,降低主频而起到节能的目的,但是当数据库系统突然负载增加,如果cpu睡眠过深,在唤醒时可能会导致cpu hang现象或触发linux bug, 所以对于数据库服务器建议禁用c state. 同样适用于oracle、pg、MySQL, 在Oracle上的故障案例可以查找我之前的博客。
文件限制
一个负载很大的系统使用大量的套接字和进程。这需要打开的文件和自定义限制,而不是默认限制
* soft nofile 500000 * hard nofile 500000 root soft nofile 500000 root hard nofile 500000 postgres soft nofile 500000 postgres hard nofile 500000
时间同步
建议配置数据库服务器的时间同步服务,如linux7前使用NTP, linux 7后默认使用chronyd ,而对于分库或分布式数据库环境, 时间同步尤其重要, 在Oracle RAC中同样对时间同步有严格要求。
如果配置了NTP服务,为了避免时间后退,需要修改ntp的配置文件。
将/etc/sysconfig/ntpd文件中的OPTIONS=-u ntp:ntp -p /var/run/ntpd.pid -g”修改为OPTIONS=”-x -u ntp:ntp -p /var/run/ntpd.pid -g”
为操作系统预留足够的内存
数据库多数会配置buffer cache缓冲区,减少物理IO或I/O合并操作,PostgreSQL的shared_buffer参数,多数建议为RAM的25% ~ 40%,Oracle有SGA、PGA,同常OLTP是60%,而MySQL也有类似的参数,innodb_buffer_pool_size一般是要设置成总内存的60-80% 。当然也不是这么简单,因为都是进程模式,如果有链接池需要为维护进程预留内存,而对于使用本地文件系统的数据库需要预留OS层的CACHE.
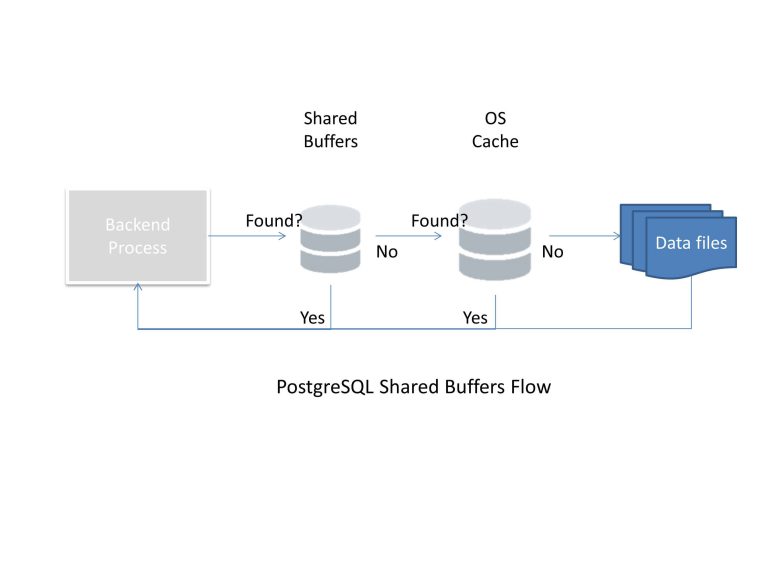
OS预留够足够的资源,才能保证上层的应用稳定,如果OS内存都吃紧给数据库分配再多内存也可能因为OS内存不足导致HANG, 从上图可知postgresql是双重cache,DB 的shared_buffer和OS 的文件系统cache,并且PostgreSQL是倾向于OS的cache的,那么就有可能一份数据,既在OS的cache中,又在PostgreSQL自身的share buffer中,这样岂不是造成了内存的浪费, Postgresql考虑到了这点,数据库层采用的是——NFU(Not FrequentlyUserd)的变体来控制shared buffer, OS的cache层采用的是LRU算法。
针对某些数据重用率不高的应用,Shared Buffer Pool设置的太大,反而会挤占OS CACHE的容量,从而让数据库的整体性能变得更差。而实际上,如果我们的应用是能够重复访问相同的数据的情况下,比如写入操作比较少,读操作比例比较高的数据库中,设置一个较大的shared buffers,提升cache命中率,是能够获得较好的性能。在PostgreSQL数据库的缓冲区管理中,我们还必须考虑如何平衡Shared Buffers和OS CACHE。多数场景因为错误的配置了数据库内存参数或没有使用hugepage,产生OOM Kill终止了PostgreSQL进程.

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~


对不起,这篇文章暂时关闭评论。