浅谈数据库与GPU?
最近有客户咨询数据库可不可以使用GPU (Graphics processing unit)来给数据库负载加速, GPU 是专用的高度并行硬件加速器,最初设计用于加速图像的创建。最近,人们一直在寻找GPU来加速其他工作负载, 对于GPU的非显卡使用场景最火的当属对于虚拟货币的挖矿,如比特币,早在2009年附近第一次听一爱投资同事说要不要买点比特币,当时一个才不足¥1000,现在看看已经升到¥14.9W,感叹自己注定是个劳碌命,当时没听他的没买币也没炒股,而是听了他另一个建议囤域名。靠倒腾域名赚到第一桶金,投资公司比肩BAT,这传奇人生只在美团创始人身上上演,而我的域名续了5-6年费后无人问津,最后一个砸在了我的手里10多年就是anbob.com. 各种虚拟机炒起来后,还在我们Linux服务器上发现被植入了挖矿病毒,当然服务器很少安装GPU,矿机的算法稀缺使用CPU几乎颗粒无收。那GPU比CPU的复杂并行强劲很多,数据库上使用缺很少呢?
硬件环境提高数据库性能的几种方法:
1. 类似的垂直扩展
2. 异质垂直扩展
3. 水平扩展
如同数据库发展的技术路径线, 有的选择数据库分布式做水平扩展,降维后以数量补单机缺陷,而另一类深耕集中式数据库优化,集中精力发展数据库内核,让底层资源问题交给硬件发展,偏激一点可以理解除了极高的并发,否则分布式数据库没有存在的必要,如CPU,内存、存储足够的强大,或底层资源去完成分布式融合,如分布式存储。因为单机的数据库资源调用、锁管理、一致性要比多机协调更高效。不过硬件也从未停步,比如新兴硬件与技术SSD 、NVMe、PMem、 多核、IB、GPU、DDR5、软件定义存储、RDMA、NVMe-oF等,Oracle 的Exadata和国产星环科技的大数据一体机就是个比较成功的案例。
那GPU使用的案例确实并不多,而使用GPU就属于异质垂直扩展,Oracle的女神级人物Maria Colgan表示GPU 对 OLTP 风格的工作负载几乎没有用处,也表示如果是几个数值的算数运算可能CPU要优于GPU, 而对于1亿个数字并行计算使用GPU才更有意义,其高度并行的结构使它们比通用 CPU 更高效,适用于并行处理大量数据的算法。如果把数据库使用上GPU性能瓶颈可能是将数据从 Oracle 数据库内存结构复制到 GPU 内存,和多个视频卡和大量GPU RAM 上大量资金投入,及数据修改需要维护GPU副本,将数据复制到GPU是不值得的,不如在CPU上运行查询。 对于OLAP场景Oracle引入了INMEMORY, 列式内存格式来大大加快分析速度。列式内存算法广泛使用 CPU 中已有的 SIMD 矢量指令。SIMD 矢量指令受益于对当前 CPU 插槽中存在的超大缓存和内存带宽的完全访问权限。SIMD 矢量指令的一个优势是,它们存在于所有现有 CPU 中,在现有硬件之上不需要进一步增加成本、复杂性或功耗。
Maria Colgan表示Oracle 正在积极与主要 GPU 供应商合作,以实现使用这些设备的数据库算法。但是当前一代的GPU有几个缺点:
1,它们主要面向浮点和其他数值处理。因此,这些设备中可用的绝大多数处理能力对于加速数据库算法没有用处。
2, 这些设备位于 PCI 总线上,无法直接访问服务器的 DRAM 内存。相反,GPU 有自己的本地高带宽内存,但此本地内存的大小比服务器内存小一到两个数量级。GPU 处理的所有数据都必须通过 PCI 总线从主 CPU 来回移动。
GPU对于区块链和图形处理、深度学习应用程序非常有效,大量并行计算引擎擅长加速需要对少量数据进行大量计算的任务。而对于大数据量分析查询,由于正在处理的数据远大于本地 GPU 内存所能容纳的数据,因此数据必须在 PCI 总线上来回移动。这会将 PCI 总线带宽的总吞吐量限制为显著低于本地内存带宽。Oracle 正在通过进一步利用 SIMD 矢量指令和改进并行性来积极改进其分析算法来缩小ORACLE 使用CPU与GPU的差距,认为GPU可能适用于那些开源未做优化的数据库。
而在PostGreSQL生态中的PG-Strom就是一种使用PG使用GPU的方案,PG-Strom是PostgreSQL的一个扩展模块,专为版本11或更高版本设计,它可以加速SQL工作负载以进行数据分析或大数据的批处理。其核心功能是GPU代码生成器,可根据SQL命令自动生成GPU程序,异步并行执行引擎在GPU设备上运行SQL工作负载。最新版本支持 SCAN(评估 WHERE 子句)、JOIN 和 GROUP BY 工作负载。在GPU处理具有优势的情况下,PG-Strom取代了PostgreSQL的原版实现,并透明地从用户和应用程序工作。PG-Strom的特征之一是GPUDirect SQL,它绕过CPU/RAM将数据从NVME / NVME-oF直接读取到GPU。GPU 上的 SQL 处理可最大化这些设备的带宽。
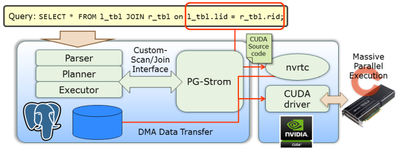
加载 PG-Strom 后,在 GPU 上运行 SQL 不需要特殊说明。它允许用户自定义 PostgreSQL 的扫描方式,并为可在 GPU 上运行的扫描/加入逻辑提供其他解决方法。如果预期成本合理,任务管理器将放置自定义扫描节点,而不是内置查询执行逻辑。 GPU的环境太少,网上找到了Hans-Jürgen Schönig几年前一个测试,转一个group by的测试,500万行记录的group by 执行时间不使用GPU是3965.495 ms,而使用GPU后执行计划
test=# explain analyze SELECT count(*) FROM t_test WHERE sqrt(x) > 0 GROUP BY y; QUERY PLAN ------------------------------------------------------------------------------------------ HashAggregate (cost=176230.88..176230.89 rows=1 width=101) (actual time=2004.355..2004.356 rows=1 loops=1) Group Key: y -> Custom Scan (GpuPreAgg) (cost=11929.24..171148.30 rows=75 width=108) (actual time=1151.310..2003.868 rows=76 loops=1) Bulkload: On (density: 100.00%) Reduction: Local + Global Device Filter: (sqrt((x)::double precision) > '0'::double precision) -> Custom Scan (BulkScan) on t_test (cost=8929.24..167897.55 rows=5000001 width=101) (actual time=12.956..1152.273 rows=5000000 loops=1) Planning time: 0.550 ms Execution time: 2299.633 ms (9 rows)
这个测试是对于Group by 排序带来的提升,许多查询根本不会从 GPU 中受益。需要更多的验证,无法预估。
我认为数据库结合GPU应用场景少的另一个原因,是其它数据库软件的崛起如一些列存、KV式NEW SQL,如ES、ClickHouse在大数据统计领域使用软件架构设计消除了 GPU 的主要优势之一, 符合现在多行业的发展规律,替换某一产物的不一定是同行对手,而是跨行业的新产物, 回到开始客户的疑问,现阶段看确实GPU对我们在数据库负载提升,从多方面考虑没有太大的诱惑。
— over —

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~


对不起,这篇文章暂时关闭评论。