生活和工作中处处面临的选择,像《皮囊》书中医生总是会让病人家属选择用药是进口还是国产? 看到这段时有过相同经历的普通人都有共鸣。 处理故障中也是尤其是RAC, 常常遇到RAC部分节点无法启动加入cluster,有时需要重启幸存节点。这是客户又会让你保证重启是否一定能起来?会不会更差?
近日一客户的4节点RAC,有三个节点CRS驱逐已crash(node 1,2,4),CRS无法启动,只有node 3目前实例还可以连接, 联系我时现场已经把1,2,4主机重启,问题依旧,先查检幸存节点是否正常, 登录node3 实例执行一些SQL查询hang挂起, 询问是否有过什么变更,答下午node3有部分存储链路问题,硬件工程师维修过。
分析方法:
— 因为输出无法拿出,仅记录方法
# on node3
$ vmstat 1 10
-- 注意B列值 有几十个,表示处理I/O or network blocked.
$ ps -elf|awk ' $2=="D" {print $0}'
--检查进程状态
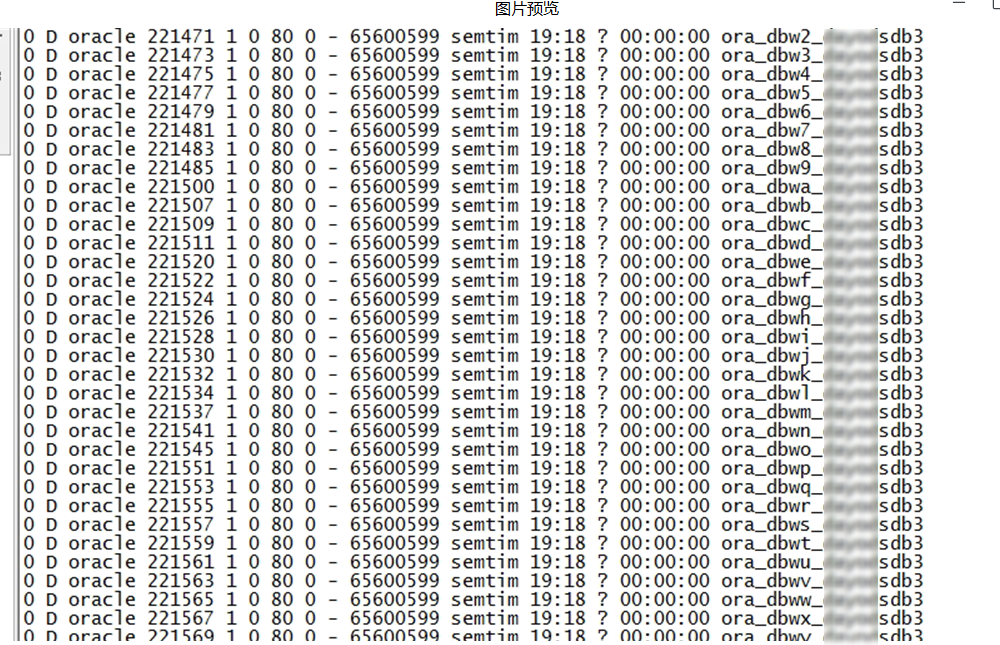 $ ps -elf|awk ' $2=="D" {print $0}'|wc -l
--有近6000多进程挂起, 其中有上图的oracle的一些关键后台进程(db writer)。
$ ps -elf|awk ' $2=="D" {print $0}'|wc -l
--有近6000多进程挂起, 其中有上图的oracle的一些关键后台进程(db writer)。
Processes in a “D” or uninterruptible sleep state are usually waiting on I/O. The ps command shows a “D” on processes in an uninterruptible sleep state. The vmstat command also shows the current processes that are “blocked” or waiting on I/O. The vmstat and ps will not agree on the number of processes in a “D” state, so don’t be too concerned. You cannot kill “D” state processes, even with SIGKILL or kill -9. As the name implies, they are uninterruptible. You can only clear them by rebooting the server or waiting for the I/O to respond. It is normal to see processes in a “D” state when the server performs I/O intensive operations.
PROCESS STATE CODES
Here are the different values that the s, stat and state output specifiers (header “STAT” or “S”) will display to describe the state of a process:
D uninterruptible sleep (usually IO)
R running or runnable (on run queue)
S interruptible sleep (waiting for an event to complete)
T stopped, either by a job control signal or because it is being traced.
W paging (not valid since the 2.6.xx kernel)
X dead (should never be seen)
Z defunct (“zombie”) process, terminated but not reaped by its parent.
$ cat /var/log/message.log server kernel: lpfc_scsi_prep_dma_buf_s3: Too many sg segments from dma_map_sg. Config 64, seg_cnt 128 server kernel: lpfc_scsi_prep_dma_buf_s3: Too many sg segments from dma_map_sg. Config 64, seg_cnt 128 ... server kernel: lpfc_scsi_prep_dma_buf_s3: Too many sg segments from dma_map_sg. Config 64, seg_cnt 128
TIP:
看到fc scsi可以想到是存储相关lpfc模块, 可能与HBA卡相关, 报错中出现了2个值64、128,该错误意味着每个SCSI 命令的最大段数不够,上层实际上正在发送大小为 128段的请求,而实际当前lpfc_sg_seg_cnt 计数为默认值(64)。用以下命令可以确认:
# cat /sys/module/lpfc/parameters/lpfc_sg_seg_cnt
这里的 IO 接口 SG_IO 很少被应用程序使用,甚至是RHEL文件系统内部,通常只有专门的存储或集群工具使用。 这表明之前有过主机系统上变动导致驱动配置不再兼容,现在发送这些大型 SG 列表失败。
此时其它节点主机已重启完毕, 启动报错查看db instance alert log ,DB Instance控制文件I/O 请求超时, ENQUEUE CF无法获取wait 120s后终止。 客户可能会把选择题交给我们, 基于当前的场景判断,当然我建议把幸存的NODE3 重启, 因为node3目前虽然活着,但是I/O挂起已经影响了其它实例的正常I/O请求, 同时node3也已经无法正常查询。 大量的进程是D状态,可能db instance无法正常关闭。
解决方法:
实际shutdown时确实长时间无法终止,采用了shutdown abort方式, 后reboot NODE3操作系统, 此时node 1,2,4实例正常启动。
重启后NODE3 已旧OS报错相同日志,但node3 CRS无法启动不会影响现有其它3个Node。 存储更换HBA卡后恢复正常。