Troubleshooting Select 产生Redo分析案例
众所周知, 在oracle数据库中redo日志是非常重要的文件,oracle代码设计根据Write-Ahead-Logging预写协议,DBW不会在LGWR写入描述该块更改方式的redo之前将已更改的块写入磁盘, redo 日志文件中记录了所有的数据库变化,通常对于Select 查询类并不会修改数据,也不应该产生redo 记录,但是还是有几种特殊场景, 前几日一个客户提出疑问,他注意到在数据库SQLPLUS中set autotrace on中执行一条查询总是出现大量的redo和伴随physical read, 环境Oracle 11.2.0.4 RAC on AIX.
现象
如下:
SQL> set autotrace on
SQL> select /*+full(a) */ count(buss_id) from ANBOB.TAB_LARGE_TABLE_LOG a;
COUNT(BUSS_ID)
-------------------
19721478
Execution Plan
----------------------------------------------------------------------------------------
Plan hash value: 3388132658
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|Time |
------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 5 | 147K (1)|00:29:29 |
| 1 | SORT AGGREGATE | | 1 | 5 | | |
| 2 | TABLE ACCESS FULL| TAB_LARGE_TABLE_LOG | 19M| 93M| 147K (1)|00:29:29 |
------------------------------------------------------------------------------------------
Statistics
------------------------------------------
0 recursive calls
0 db block gets
864313 consistent gets
805988 physical reads
23439672 redo size
535 bytes sent via SQL*Net to client
520 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
Note:
执行计划使用full table scan,表中约有2000万记录,产生了23M的redo, 805988物理读,864313逻辑读。连续第二次执行同样有60万物理读和18M redo size。
猜测
遇到该问题时我们先大胆的猜测,如果凭经验select产生redo多数是与延迟块清除(delayed block cleanout)有关,物理读原因要么是使用了直接路径读(direct path read), 因为直接路径读是直接把数据从磁盘读取到PGA中,不会把block内容写回磁盘,所以多次读取相同的块也会反复的做块清除.(MOS 1925688.1记录了此行为), 采用直接路径读取,如果表记录没有改变有可能相同数目的延迟块清除操作。direct path read的清除操作仅是针对从磁盘上读取到PGA内存中的block 镜像,而不对实际disk上的块做任何修改,所以不会任何redo,无法解释redo;
————————————————————————————————————————————————————–
注:Select会产生延迟块清除生成redo。如果一个事务,由于部分block在commit之前已经写回datafile(如flush buffer_cache), 或者事务修改的block数过多,则commi的时候只会清理undo segment header中的事务表信息,data block上的ITL事务 flag不会清除,否则因为commit时已刷到disk上的block再加载一次内存代价过高。那么在下一次读取这些block时,需要将block ITL中的事务flag进行清除,就发生了select还将“修改”这些修改后的block而产生redo。
PostgreSQL也实现了类似Oracle的延迟块清除工作,如果一个数据块被读到内存中,做多版本判断时发现其中的行记录的事务都已提交的,会给行记录设置一个标志位表示该记录可见的,以后不需要再到commit log中去查看其事务状态,所以PostgreSQL与Oracle数据库一样,一些select操作也会产生一些写I/O.
————————————————————————————————————————————————————–
另一种情况是因为使用了全表扫描(FULL TABLE SCAN),全表扫块会把block放到Buffer cache LRU的冷端,对于ORACLE是多进程共用buffer cache,读取新的块数量较多的情况下,后续读取的块有可能把之前cached block置换出去,导致每次读取都会有不同数量物理读, 但是这种也不会产生redo,需要配合大量的表数据更新和延迟块清除,通常可以通过dba_tab_modifications判断一下判断table时间段内是否有UPDATE操作;
另一种情况是select一致读时构造CR块,如会话1对表做了DML修改,未提交前,会话2对相同表数据执行查询需要构造CR block,修改内存中的数据块,产生REDO;
也有可能是select查询触发了递归SQL,如审计、trigger其它事务,产生了redo,这种可以启用10046\SQL trace跟踪是否存在级连SQL;
如果没有一套完整的运维工具,把专家经验整合一一排查,很难在第一时间考虑周全,尤其是在Oracle不同版本中有些特性的变化DBA也未必能快速的做出判断,以上的猜测全吗?当然不,下面的案例就是另一种可能,也许产生redo还有其它场景, 我们就有了猜测, 然后去验证,毕竟分析问题的过程才是对DBA成长更有帮助。 Why guess when you can kown?
分析方法
对于性能数据问题,通常可以把Top SQL , Top event作为故障诊断的起点,有时还需要从session statistics结合指标分析,这点是其它数据库无法和ORACLE 数据库媲美的,在oracle 数据库中session状态指标丰富,19c已达2000有余。因此Top event无法很好地解释问题时,需要更深入地研究性能数据,更甚oracle提供大量的diag event, 揭开oracle这个黑盒中部分神秘功能的面纱。
想要了解会话级性能数据的我们通常使用的数据及其顺序:
1, TOP Event/ TOP SQL
2, V$SESSTAT Statistics
3, Dump trace
有时候看#1就足够了,经常需要看#1和#2,如果还无法解释时需要看#3。#3需要更高级的诊断能力和内部资料,如需要如何阅读sql trace, 10053 trace, hanganalyze, systemstate, processtate , file dump …
在诊断性能问题时我还是比较喜欢使用TanelPoder大师的snapper工具,同样也我推荐给大家,它是使用SQL同时取得#1和#2的session 数据,提升分析效率。
像本案例的select产生redo的疑问,我们也可以dump SQL执行时段的redo file,但是也需要一些小技巧,如在做dump 前先做一次log file switch , 然后多次连续的执行上面的产生redo的Select查询,然后dump redo logfile, redo logfile dump trace中有 redo OP code, 从网上可以找到一些公开的OP code对应, 然后自己写一段shell 格式化一下,就可以找出记录占用较高的OP code,如OP 4.1 对应Block cleanout record;当然通常分析redo日志也可以尝试logmner工具解析。
案例分析
言归正传,分析上面一条select 产生redo的问题,因为SQL是固定的,我们先排除有audit或trigger等触发的级联SQL, 做10046 event, 在trace中发现都是这个表的物理读,未发现其它对象,trace中 event和查询v$session_event一致,但是注意10046 trace中并不会反映延迟块清除(delay block cleanout),我们先来看TOP event.
SQL> select sid se_sid,event se_event,time_waited/100 se_time_waited,total_waits,total_timeouts,average_wait/100 average_wait,max_wait/100 max_wait
from v$session_event
where sid in(2663);
SE_SID SE_EVENT SE_TIME_WAITED TOTAL_WAITS TOTAL_TIMEOUTS AVERAGE_WAIT MAX_WAIT
---------- --------------------------------- -------------- ----------- -------------- ------------ ----------
2663 Disk file operations I/O .01 28 0 .0003 .01
2663 db file sequential read 1.2 5556 0 .0002 .03
2663 db file scattered read 28.85 22624 0 .0013 .02
2663 gc cr multi block request 5.94 15270 0 .0004 .01
2663 gc cr grant 2-way .32 2842 0 .0001 0
2663 library cache pin 0 4 0 .0002 0
2663 library cache lock 0 4 0 .0002 0
2663 SQL*Net message to client 0 16 0 0 0
2663 SQL*Net message from client 63.79 15 0 4.2529 22.89
2663 events in waitclass Other 0 1 0 0 0
10 rows selected.
NOTE:
这里并没有看到direct path read,基本可以排除直接路径读,这点也可以session级修改”_serial_direct_read”=false,禁用串行直接路径读,在不使用并行的情况问题依旧可以重现该问题,基本上是db file scattered read和db file sequential read。
第二步我们看Session statistics 从v$sesstat,但是注意v$sesstat是累计值,所以需要取session运行select SQL前后2次v$sesstat值的差异,在运行SQL前建议创建新session,这样session stat指标值几乎都为0.
v$sesstat中对于”delayed block cleanout”的statistics name 的值如下:(注意在oracle有些版本中有可能名称不同)
– “cleanouts only – consistent read gets”
– “cleanouts and rollbacks – consistent read gets”
如果构建cr块产生redo,通过v$sesstat 查看statistics name的值:
– “data blocks consistent reads – undo records applied “
– “cleanouts and rollbacks – consistent read gets”
不过客户一再表示他们不存在大量的update,当然有些时候为了排除干扰,不要相信认何人说的话,除非你亲眼看到, 因为一开始客户反馈select的table没有update,但dba_tab_modification确实有。
收集sql运行的session stats:
1, query v$sesstat #1 on session 2
2, run select SQL on session 1
3, query v$sesstat #2 on session 2
然后对比差异第1步和第2步的差异, 当然为了更好方便,可以创建global temporary table用于存放两次v$sesstat的数据,SQL对比差异,现场客户反馈的v$sesstat变化数据时过滤掉了值为0的记录,同时也重现了产生redo的现象。
拿到session statistics数据,从v$sessstat我们先以cleanout为关键字没有找到我们想要的内容,这里篇幅原因只截取了部分关注的,那我们再看redo 部分.
— 第一次
SID NAME VALUE
---------- ---------------------------------------------------------------- ----------
2657 physical read total IO requests 35024
2657 physical read total multi block requests 10560
2657 physical read total bytes 6602653696
2657 physical reads 805988
2657 physical reads cache 805988
2657 physical read IO requests 35024
2657 physical read bytes 6602653696
2657 db block changes 68
2657 redo entries 35031
2657 redo size 23449636
2657 redo entries for lost write detection 34290
2657 redo size for lost write detection 22281124
2657 undo change vector size 8676
2657 data blocks consistent reads - undo records applied 2
2657 rollbacks only - consistent read gets 2
2657 table scans (long tables) 1
— run select generate redo SQL 1 times
— 第二次
SID NAME VALUE
---------- ---------------------------------------------------------------- ----------
2657 physical read total IO requests 70194
2657 physical read total multi block requests 21038
2657 physical read total bytes 1.3207E+10
2657 physical reads 1612135
2657 physical reads cache 1612135
2657 physical read IO requests 70194
2657 physical read bytes 1.3207E+10
2657 db block changes 95
2657 redo entries 70204
2657 redo size 46879924
2657 redo entries for lost write detection 69215
2657 redo size for lost write detection 45355776
2657 redo subscn max counts 1
2657 undo change vector size 11684
2657 data blocks consistent reads - undo records applied 6
2657 rollbacks only - consistent read gets 4
2657 table scans (long tables) 2
Note:
产生了新35173 redo entries,其中34925为for lost write detection占用redo size 90%,这也就是为什么此SQL产生大量REDO 的原因,其它少量有可能是维护或undo CR操作相关的, 现在主要是redo entries for lost write detection,从名称我们可以猜测是与‘写丢失发现’特性相关.
如果dump redo file可以看到这部分redo record, lost write detection 的redo block 叫做Block read record (BRR), 对应的redo OP code为23.2, dump redo可以使用:
SQL> alter system dump logfile '***redo_log_.log' layer 23 opcode 2;
trace 内容如下:
REDO RECORD - Thread:1 RBA: 0x00000e.00000039.0010 LEN: 0x0060 VLD: 0x14
SCN: 0x0000.0039c159 SUBSCN: 1 02/24/2021 09:52:03
(LWN RBA: 0x00000e.00000039.0010 LEN: 0001 NST: 0001 SCN: 0x0000.0039c159)
CHANGE #1 TYP:0 CLS:4 AFN:4 DBA:0x01008182 OBJ:92352 SCN:0x0000.00398585 SEQ:1 OP:23.2 ENC:0 RBL:0
Block Read - afn: 4 rdba: 0x01008182 BFT:(1024,16810370) non-BFT:(4,33154)
scn: 0x0000.00398585 seq: 0x01
flags: 0x00000004 ( ckval )
“写丢失发现”功能是否打开? 检查参数
SQL> show parameter DB_LOST_WRITE_PROTECT NAME VALUE ---------------------------------------- ---------------------------------------- db_lost_write_protect TYPICAL
写丢失发现(lost write detection)
写丢失(lost writes):“当I / O子系统确认块写入已完成,而实际上在持久存储中未发生写入时,就会发生数据块丢失写入”,丢失的写操作可能是由存储故障引起的,也有可能RAM中的数据(例如buffer cache)和磁盘存储之间的任何错误引起,也有可能是Oracle bug。 如block x中的值为1,update操作把1值从磁盘读到buffer cache中并修改为2, 然后DBW再把该IO请求发给OS,OS层答复IO完成,实际存储原因丢掉了这个IO,或因为其它原因写入了旧的数据, 那disk上的值还是之前的数据值1,从而导致了写丢失,同时使用rman或dbv并不会发现,因为对于它们旧数据块也是完整的,块本身是一致的,没有损坏。DBA不会注意到它。
lost write detection功能引入用来发现该问题,Dataguard环境,当 主库和备库db_lost_write_protect配置为TYPICAL或FULL时(区别表空间读写类型),primary DB当select时块从disk上读到buffer cache中执行物理读取时,会生成其他redo条目,附加lost write detection需要的信息如block rdba、obj, 改变向量和SCN写入redo log, 据Oracle宣传开启后通常带来的性能负担可以忽略,但是建议先在测试库测试并注意REDO量的增长。然后配合DataGuard去持续的lost write验证,备用数据库上设置DB_LOST_WRITE_PROTECT = TYPICAL,这将使MRP及其恢复从属服务器使用redo日志流中的额外信息来检查丢失的写操作,当发现异常中报错并中止MRP日志应用,需要人工介入修复。
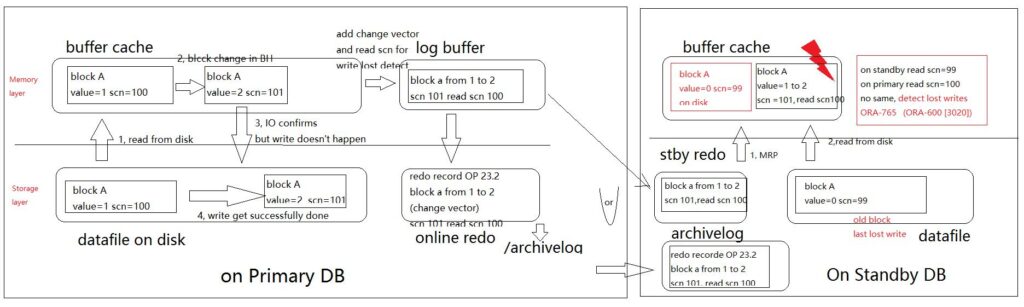
如果想手动模拟这个操作,可以使用dd命令备份、修改、恢复覆盖一个data block达到写丢失的现象,从报错ORA-10567中可以确认block地址, 从MRP进程的trace中也有记录,利用DG 的standby 做为数据库副本检测写丢失,MRP从属将开始通过比较SCN来进行额外的工作以检查丢失的写操作,可以dump redo分析附加在redo中的 BRR,BRR大小不尽相同,官方表示在64位平台一个典型的BRR redo change只有 144 bytes和40字节的 redo header, 但是从上面v$sesstat中数据for lost write detection ,redo size/redo entries达655字节( 45355776/69215),如果开户该功能需要评估在primary产生的影响。 分析该特性的session 状态可以查看v$sesstat 中查看%lost%write%统计信息,启用lost write detect 在standby上,无疑增加了额外的物理读,这也就是有些细心的同学发现standby上没有任何业务,但是物理读很高的一种可能,相关的统计信息如下:
– ‘recovery blocks read for lost write detection’
– ‘recovery blocks skipped lost write checks’
在执行介质恢复 (recover database命令)时,还将根据BRR条目中的SCN检查丢失的写操作 。因此即使Data Guard不可用,在18c版本以前也可以使用从备份中对数据库进行的简单还原来执行BRR记录的验证,以检索lost write。 该功能虽然能发现lost write, 但并不能启到保护作用,发生lost write后解决也比较复杂,MOS中1265884.1提供了解决方法。在Oracle EXDATA中默认是启用了lost write detect,db_lost_write_protect默认值为TYPICAL. 从oracle 18c开始引入新特性Shadow Lost Write Protection,在没有DG时也可以持续的做lost write 发现。
注: 12.1.0.2 版本有个 Bug 28511632 需要注意,如果rman duplicate 搭建standby database时,异常中断可能导致primary db 发生lost write,破坏生产库。
18c Shadow Lost Write Protection新特性
12cR2 之前,为了持续检测写丢失,必须配置备用数据库,并且在主库和备库都设置 DB_LOST_WRITE_PROTECT 参数,该参数设置TYPICAL后,主库实例会在 redo log 中记录从处于读写模式的表空间中读取的数据块的信息。当备库在恢复过程中应用日志时,会读取相应的数据块信息并和重做日志中记录进行数据块的 SCN 对比,以来检测主库是否有发生写丢失。
Oracle 12c R2引入了一个新特性”Shadow Lost Write Protection”,该特性可以在主库直接进行数据块写丢失检测,而无需配置备用数据库。即使配置了备用数据库,该特性也被证明对于update有益,因为在写丢失发生在持久存储后,任何查询和修改语句要求通过物理读获取这个数据块都会触发写丢失报错。这样可以使 DBA 通过介质恢复来恢复这个数据块(或数据文件/表空间)。这个特性在12c的release 2为了测试的目的而引入的,从18c开始公开可用。
1,创建一个新表空间来存 shadow data,表空间必须创建成为大文件表空间。
2,对某个用户表空间开启写丢失保护之前,需要先在数据库级别上开启写丢失保护,然后再在表空间级开启:
SQL> alter database enable lost write protection;
如果是plugaable database
SQL> alter pluggable database enable lost write protection; Pluggable database ENABLE altered.
对USERS表空间配置lost write protect
SQL> alter tablespace USERS enable lost write protection;
开启写丢失保护后,当脏数据(USERS 表空间中被更改的块)的数据块从buffer cache写入disk时,oracle 会把数据块的 SCN 写入影子表空间。这些数据可以从动态视图 V$SHADOW_DATAFILE 或它的基表X$SHADOW_DATAFILE 中查询到。
如果发现写丢失时会提示:
ORA-65478: shadow lost write protection - found lost write
同时db alert log中也会提示:
ERROR - I/O type:buffered I/O found lost write in block with file#:nn rdba:0xnnnnnnn,
注:当这些块在一致性读取期间通过buffer cache读取时,从读取它们的函数中标识了它们x$bh.fp_whr like ‘kr_gcur_4: kcbr_lost_get_lost_w%’
总结:
这个案例因为数据库启用了写丢失发现,所以在一个超大表做全表扫而物理读时,在primary DB select时产生了附加的redo信息,也告诫我们避免过早的猜测,通过获取信息和分析事实,您可以学到更多,分析这类进程级问题时,可以多得用TOP SQL, TOP EVENT和session statistics快照对比的方法,可以较容易分析问题或首选做为分析的起点,同时感谢oracle在不同的版本新功能的引入,及oracle工程一体机上新鲜事物,让我们学习工作更有激情。

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~


对不起,这篇文章暂时关闭评论。