Troubleshooting Performance event ‘control file sequential read’
前段时间整理过关于control file的一个等待《Troubleshooting performance event ‘enq: CF – contention’》, 这里再记录关于control file的另一个event( 这里没用等待), 此event只是通知类event,和db file sequential read类似为数据库的I/O类操作,但wait class并非USER I/O,而是SYSTEM I/O. 问题时段control file sequential read占到了AWR top 1 event.
常见于:
-
- making a backup of the controlfiles – rman in process
- sharing information (between instances) from the controlfile – RAC system
- reading other blocks from the controlfiles
- reading the header block
- High DML periods
- poor disk performance
- Too many control files
- frequent COMMIT
因为控制文件中记录着最后transaction的SCN,所以在OLTP类型数据库中需要频繁的更新,但通常是小i/o,但一般也很少在top event中出现,这个案例(oracle 19c RAC)中下面的AWR看到问题时间段control file sequential read占用约90%的DB TIME,比较异常。
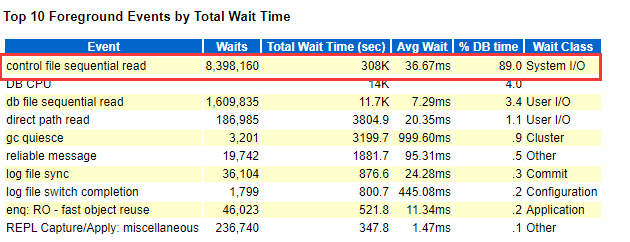
注意: control file sequential read 问题比较突出,一小时内等待了308K sec DB TIME,并均单次wait 达36.67 ms 有些慢. 但是db file sequential read和direct path read 都小于5ms,log file parallel write 也是5ms左右。有时control file wait伴随出现log file switch (archiving needed)也是受control file sequential read影响. 当然I/O Wait avg有时定位问题过于粗糙,需要通过AWR中的Wait Event Histogram 继续分析event 分布。
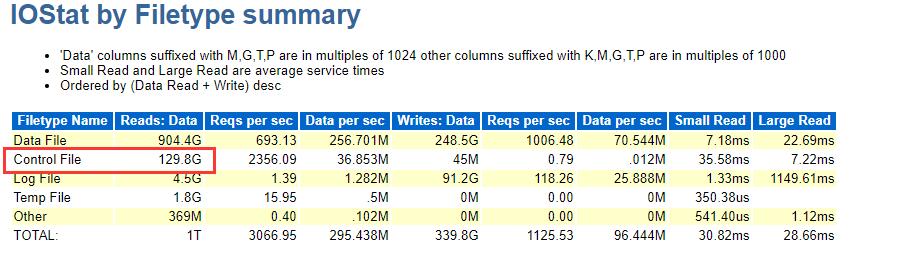
IOSTAT BY FILETYE SUMMARY 可以看出1小时时间内controlfile read约130GB, control file write 45M,,意味control file 读是非常的大。
分析思路:
1, 检查control file大小
select v.*, round(block_size*file_size_blks/1024/1024, 2) MB from v$controlfile v; select v.*, round(record_size*records_total/1024/1024, 2) MB from v$controlfile_record_section v order by MB desc; select * from v$parameter where name = 'control_file_record_keep_time';
检查结果几十MB还可以接受,有些案例是因为keep time为1年,导致contolfile文件为几百MB, 可以从v$controlfile_record_section查询占用条目。
2, 和正常时间点对比control file iostat
从异常时间点和正常时间点AWR中对比control file 相关evvent waits和IOStat by Filetype summary, 发现正常时1小时也有800多万次wait,但是平时AWR 控制文件读avg time为300 us, 所以判断问题时是I/O 比平时慢了。
3, 分析I/O性能
调取问题时间段的OSW或nmon查看iostat信息,是否存储磁盘出现io 性能问题,还要注意cpu 资源,因为cpu枯竭时,同样会影响I/O 响应时间。是否有多个控制文件存在同一磁盘?是否在存在hot block?
SELECT event, wait_time, p1, p2, p3 FROM gv$session_wait WHERE event LIKE '%control%'; SELECT event,p1, p2,sql_id,count(*) FROM gv$active_session_history WHERE event LIKE '%control%' group by event,p1,p2,sql_id; 查询结果CPU空闲,部分disk busy较高。
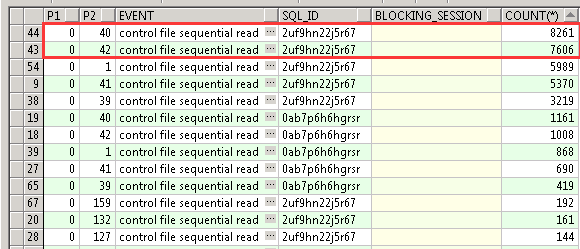
control file sequential read 可以看出主要集中在39-42# block. 1#为 file header。
4, 查找对应的session , SQL,分析执行计划
从AWR/ASH rpt或ASH 裸数据分析event对应session信息和相关SQL, 是否存在执行计划变化或不优?
从上面 step 3的结果也能发现top SQL, 该SQL主查是监控表空间使用率,session信息为Prometheus监控工具 频率调用。SQL确实存在执行计划不优,而且使用了hint 绑定,收集system statistics 去掉SQL hint后测试效率更佳,当然优化这条SQL不在本篇范围内。错误的join方式导致control file sequential read 更高。
从ASH 裸数据中我们还能定位到event wait的执行计划SQL_PLAN_LINE_ID行数和对应的对象为x$kccfn. (fixed full scan),是监控temp file使用$TEMP_SPACE_HEADER。
Control file物理读
X$中kcc开头的来自控制文件,读取control file的记录通常是每次phyical read,并不做cache,下面做个测试.
select * from v$fixed_view_definition where lower(view_definition) like '%x$kcc%'; 如v$tablespace,v$dbfile ,v$tempfile, v$datafile,gv$archive, 正如这个案例中是一个常用的查询表空间使用率的SQL, 查询了dba_data_file和DBA_TEMP_FILES,$TEMP_SPACE_HEADER等 依赖关系dba_data_files 基于v$dbfile 基于gv$dbfile 基于x$kccfn 更多内容可以查看《ASM Metadata and Internals》 session级打开10046 event,2次或多次查询x$KCCFN 查看control file read block. select * from x$kccfn; $cat /..._ora_1841.trc|grep "control file sequential read" WAIT #140285876517504: nam='control file sequential read' ela= 14 file#=0 block#=1 blocks=1 obj#=-1 tim=67389713130731 WAIT #140285876517504: nam='control file sequential read' ela= 4 file#=0 block#=15 blocks=1 obj#=-1 tim=67389713130755 WAIT #140285876517504: nam='control file sequential read' ela= 4 file#=0 block#=17 blocks=1 obj#=-1 tim=67389713130769 WAIT #140285876517504: nam='control file sequential read' ela= 5 file#=0 block#=90 blocks=1 obj#=-1 tim=67389713130785 WAIT #140285876517504: nam='control file sequential read' ela= 5 file#=0 block#=92 blocks=1 obj#=-1 tim=67389713131972 WAIT #140285876517504: nam='control file sequential read' ela= 12 file#=0 block#=1 blocks=1 obj#=-1 tim=67389714364091 WAIT #140285876517504: nam='control file sequential read' ela= 6 file#=0 block#=15 blocks=1 obj#=-1 tim=67389714364128 WAIT #140285876517504: nam='control file sequential read' ela= 5 file#=0 block#=17 blocks=1 obj#=-1 tim=67389714364152 WAIT #140285876517504: nam='control file sequential read' ela= 7 file#=0 block#=90 blocks=1 obj#=-1 tim=67389714364177 WAIT #140285876517504: nam='control file sequential read' ela= 7 file#=0 block#=92 blocks=1 obj#=-1 tim=67389714365201
TIP:
发现每次control file read都是相同的物理读,相同的文件和块号,当然controlfile 文件号不同于datafile总为0,但block号也是能看出。如果对比session stat也能发现session级的physical read total IO requests是增涨的,但是physical reads并不会增加。
ASM Fine Grained Striping细粒度条带
ASM 提供了2种上条带,一是Coarse 粒度为1AU 也可以认为不做条带,用完一AU再用下一AU; 另一种是Fine Grained细粒度为了更加分散文件分布和降低IO延迟,可以指定几个 AU做条带,单次IO大小,有两个参数控制,默认为IO大小128k。如1MB AU SIZE, 条带宽度为2,大小为128k,使用分布如下图。
SQL> @p stripe NAME VALUE ---------------------------------------- ---------------------------------------- _asm_stripewidth 2 _asm_stripesize 131072
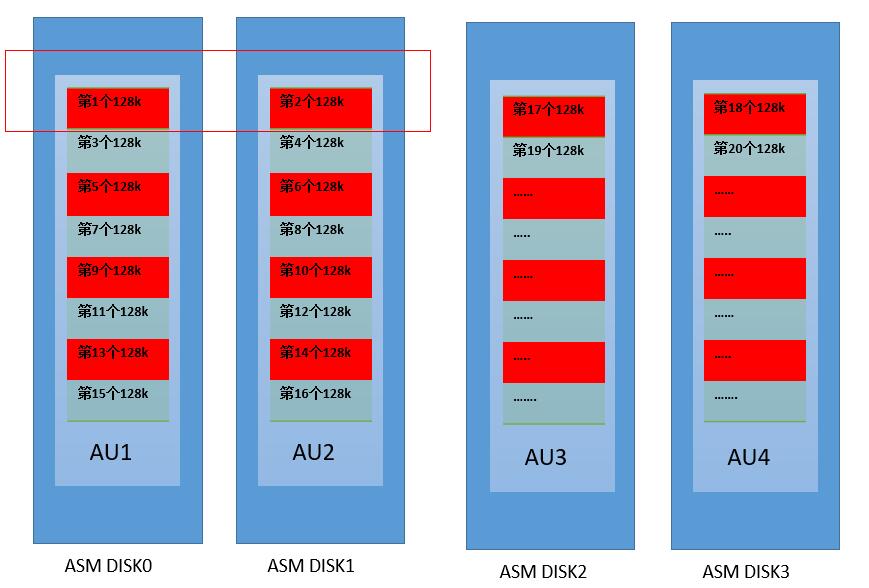
根据contro file block找DISK.
如本案例中先不说SQL效率问题,明显是有I/O变慢导致control file sequential read等待更加显著, 上面已定位到为40# 相邻的 block. 下面我们找出控制文件40# block所在的disk ,然后查看该disk的性能。该库使用的ASM存储,并且controlfile 在ASM中默认使用的为细粒度条带化(在10g时online redo同样使用细粒度, 11g开始仅control file),这让确认相对麻烦一些。
1* select * from v$controlfile
STATUS NAME IS_ BLOCK_SIZE FILE_SIZE_BLKS CON_ID
------- -------------------------------------------------- --- ---------- -------------- ----------
+DATADG/ANBOB/CONTROLFILE/current.678.995708357 NO 16384 3372 0
+DATADG/ANBOB/CONTROLFILE/current.677.995708357 NO 16384 3372 0
+DATADG/ANBOB/CONTROLFILE/current.676.995708357 NO 16384 3372 0
OR
SQL> show parameter control
PARAMETER_NAME TYPE VALUE
------------------------------------ ----------- ----------------------------------------------------------------------------------------------------
_sql_plan_directive_mgmt_control integer 0
control_file_record_keep_time integer 31
control_files string +DATADG/ANBOB/CONTROLFILE/current.678.995708357, +DATADG/ANBOB/CONTROLFILE/current.677.995708357
, +DATADG/ANBOB/CONTROLFILE/current.676.995708357
control_management_pack_access string DIAGNOSTIC+TUNING
SQL> select GROUP_NUMBER,FILE_NUMBER,BLOCK_SIZE,BLOCKS,BYTES,TYPE,REDUNDANCY,STRIPED from v$asm_file where type='CONTROLFILE';
GROUP_NUMBER FILE_NUMBER BLOCK_SIZE BLOCKS BYTES TYPE REDUND STRIPE
------------ ----------- ---------- ---------- ---------- -------------------- ------ ------
2 676 16384 3373 55263232 CONTROLFILE UNPROT FINE
2 677 16384 3373 55263232 CONTROLFILE UNPROT FINE
2 678 16384 3373 55263232 CONTROLFILE UNPROT FINE
或使用
SQL> select * from v$asm_alias where file_number in(select FILE_NUMBER from v$asm_file where type='CONTROLFILE');
NAME GROUP_NUMBER FILE_NUMBER FILE_INCARNATION ALIAS_INDEX ALIAS_INCARNATION PARENT_INDEX REFERENCE_INDEX A S CON_ID
--------------------------------- ------------ ----------- ---------------- ----------- ----------------- ------------ --------------- - - ----------
Current.676.995708357 2 676 995708357 164 5 33554591 50331647 N Y 0
Current.677.995708357 2 677 995708357 163 5 33554591 50331647 N Y 0
Current.678.995708357 2 678 995708357 162 5 33554591 50331647 N Y 0
-- 查询ASM DG
SQL> select * from v$asm_diskgroup;
GROUP_NUMBER NAME SECTOR_SIZE LOGICAL_SECTOR_SIZE BLOCK_SIZE ALLOCATION_UNIT_SIZE STATE TYPE TOTAL_MB FREE_MB
------------ ---------- ----------- ------------------- ---------- -------------------- ----------- ------ ---------- ----------
1 ARCHDG 512 512 4096 4194304 CONNECTED EXTERN 2097152 2078468
2 DATADG 512 512 4096 4194304 CONNECTED EXTERN 50331648 4105196
3 MGMT 512 512 4096 4194304 MOUNTED EXTERN 102400 62044
4 OCRDG 512 512 4096 4194304 MOUNTED NORMAL 10240 9348
我们以file 676为例
— ASM FILE对应的file directory
1* select group_number,disk_number,path from v$asm_disk where group_number=2 and disk_number=0
GROUP_NUMBER DISK_NUMBER PATH
------------ ----------- ------------------------------
2 0 /dev/asm-disk1
# find file directory second au
grid@anbob:~$kfed read /dev/asm-disk1|egrep 'f1b1|au'
kfdhdb.ausize: 4194304 ; 0x0bc: 0x00400000
kfdhdb.f1b1locn: 10 ; 0x0d4: 0x0000000a
kfdhdb.f1b1fcn.base: 0 ; 0x100: 0x00000000
kfdhdb.f1b1fcn.wrap: 0 ; 0x104: 0x00000000
# find disk directory
grid@anbob:~$kfed read /dev/asm-disk1 aun=10 aus=4194304 blkn=1|grep au|grep -v 4294967295
kfffde[0].xptr.au: 10 ; 0x4a0: 0x0000000a
kfffde[1].xptr.au: 121954 ; 0x4a8: 0x0001dc62
grid@anbob:~$kfed read /dev/asm-disk1 aun=10 aus=4194304 blkn=1|grep disk|grep -v 65535
kfffde[0].xptr.disk: 0 ; 0x4a4: 0x0000
kfffde[1].xptr.disk: 21 ; 0x4ac: 0x0015
file directory metadate位置有disk 0 au 10,disk 21 au 121954, 因为AU SIZE 4MB, metadata block size 4096,ASM为了管理方便会给每个文件目录分配一个唯一的编号,并且会在第一个文件目录的AU里面为其分配1个4k的block来存放它分配的AU情况。 所以一个AU SIZE可以记录4M/4K =1024个 file directory, 我们的676# file在第一个AU 中,也就是disk0 au10.
— 从file directory 查找676# FILE的AU 分布
grid@anbob:~$kfed read /dev/asm-disk1 aun=10 aus=4194304 blkn=676|grep disk|grep -v ffff kfffde[0].xptr.disk: 6 ; 0x4a4: 0x0006 kfffde[1].xptr.disk: 43 ; 0x4ac: 0x002b kfffde[2].xptr.disk: 26 ; 0x4b4: 0x001a kfffde[3].xptr.disk: 15 ; 0x4bc: 0x000f kfffde[4].xptr.disk: 3 ; 0x4c4: 0x0003 kfffde[5].xptr.disk: 10 ; 0x4cc: 0x000a kfffde[6].xptr.disk: 20 ; 0x4d4: 0x0014 kfffde[7].xptr.disk: 41 ; 0x4dc: 0x0029 kfffde[8].xptr.disk: 28 ; 0x4e4: 0x001c kfffde[9].xptr.disk: 2 ; 0x4ec: 0x0002 kfffde[10].xptr.disk: 40 ; 0x4f4: 0x0028 kfffde[11].xptr.disk: 47 ; 0x4fc: 0x002f kfffde[12].xptr.disk: 42 ; 0x504: 0x002a kfffde[13].xptr.disk: 17 ; 0x50c: 0x0011 kfffde[14].xptr.disk: 27 ; 0x514: 0x001b kfffde[15].xptr.disk: 18 ; 0x51c: 0x0012 grid@anbob:~$kfed read /dev/asm-disk1 aun=10 aus=4194304 blkn=676|grep au|grep -v ffff kfffde[0].xptr.au: 3 ; 0x4a0: 0x00000003 kfffde[1].xptr.au: 3 ; 0x4a8: 0x00000003 kfffde[2].xptr.au: 2 ; 0x4b0: 0x00000002 kfffde[3].xptr.au: 8 ; 0x4b8: 0x00000008 kfffde[4].xptr.au: 2 ; 0x4c0: 0x00000002 kfffde[5].xptr.au: 10 ; 0x4c8: 0x0000000a kfffde[6].xptr.au: 3 ; 0x4d0: 0x00000003 kfffde[7].xptr.au: 3 ; 0x4d8: 0x00000003 kfffde[8].xptr.au: 213918 ; 0x4e0: 0x0003439e kfffde[9].xptr.au: 213929 ; 0x4e8: 0x000343a9 kfffde[10].xptr.au: 213922 ; 0x4f0: 0x000343a2 kfffde[11].xptr.au: 213927 ; 0x4f8: 0x000343a7 kfffde[12].xptr.au: 213922 ; 0x500: 0x000343a2 kfffde[13].xptr.au: 213923 ; 0x508: 0x000343a3 kfffde[14].xptr.au: 213928 ; 0x510: 0x000343a8 kfffde[15].xptr.au: 213921 ; 0x518: 0x000343a1 SQL> @p stripe NAME VALUE ---------------------------------------- ---------------------------------------- _asm_stripewidth 8 _asm_stripesize 131072
可以看到676# file分配了16个AU, 当前的细粒度宽度为8,刚好为2组AU.
— 验证一个AU内容是否为控制文件内容
SQL> select group_number,disk_number,path from v$asm_disk where disk_number=6;
GROUP_NUMBER DISK_NUMBER PATH
------------ ----------- ------------------------------
2 6 /dev/asm-disk15
# dd if=/dev/asm-disk15 bs=4194304 skip=3 count=1|strings|more
...
+DATADG/ANBOB/DATAFILE/netm_dat.458.995715183
+DATADG/ANBOB/DATAFILE/netm_dat.459.995715187
+DATADG/ANBOB/DATAFILE/rpt_bill.460.995715311
+DATADG/ANBOB/DATAFILE/netm_dat.461.995715315
+DATADG/ANBOB/DATAFILE/netm_dat.462.995715315
+DATADG/ANBOB/DATAFILE/rpt_bill.463.995715317
+DATADG/ANBOB/DATAFILE/netm_dat.464.995715441
+DATADG/ANBOB/DATAFILE/netm_dat.465.995715441
+DATADG/ANBOB/DATAFILE/rpt_bill.466.995715441
+DATADG/ANBOB/DATAFILE/netm_dat.467.995715441
+DATADG/ANBOB/DATAFILE/netm_dat.468.995715567
+DATADG/ANBOB/DATAFILE/rpt_bill.469.995715567
+DATADG/ANBOB/DATAFILE/netm_dat.470.995715567
— 在ASM实例中查询更加容易
如果ASM 实例可用可以直接查询x$kffxp (ASM File eXtent Pointer)
col path for a30
col failgroup for a15
select a.file_number file#,a.name,x.xnum_kffxp extent#,a.group_number group#,d.disk_number disk#,
au_kffxp au#, dg.allocation_unit_size au_size,
decode(x.lxn_kffxp,0,'PRIMARY',1,'MIRROR') TYPE, d.failgroup,d.path
from v$asm_alias a,x$kffxp x, v$asm_disk d, v$asm_diskgroup dg
where x.group_kffxp=a.group_number
and x.group_kffxp=dg.group_number
and x.group_kffxp=d.group_number
and x.disk_kffxp=d.disk_number
and x.number_kffxp=a.file_number
and lower(a.name)=lower('Current.676.995708357')
order by x.xnum_kffxp;
FILE# NAME EXTENT# GROUP# DISK# AU# AU_SIZE TYPE FAILGROUP PATH
---------- ---------------------------------------- ---------- ---------- ---------- ---------- ------- --------------- ---------------------------------
676 Current.676.995708357 0 2 6 3 4194304 PRIMARY DATADG_0006 /dev/asm-disk15
676 Current.676.995708357 1 2 43 3 4194304 PRIMARY DATADG_0043 /dev/asm-disk5
676 Current.676.995708357 2 2 26 2 4194304 PRIMARY DATADG_0026 /dev/asm-disk33
676 Current.676.995708357 3 2 15 8 4194304 PRIMARY DATADG_0015 /dev/asm-disk23
676 Current.676.995708357 4 2 3 2 4194304 PRIMARY DATADG_0003 /dev/asm-disk12
676 Current.676.995708357 5 2 10 10 4194304 PRIMARY DATADG_0010 /dev/asm-disk19
676 Current.676.995708357 6 2 20 3 4194304 PRIMARY DATADG_0020 /dev/asm-disk28
676 Current.676.995708357 7 2 41 3 4194304 PRIMARY DATADG_0041 /dev/asm-disk47
676 Current.676.995708357 8 2 28 213918 4194304 PRIMARY DATADG_0028 /dev/asm-disk35
676 Current.676.995708357 9 2 2 213929 4194304 PRIMARY DATADG_0002 /dev/asm-disk11
676 Current.676.995708357 10 2 40 213922 4194304 PRIMARY DATADG_0040 /dev/asm-disk46
676 Current.676.995708357 11 2 47 213927 4194304 PRIMARY DATADG_0047 /dev/asm-disk9
676 Current.676.995708357 12 2 42 213922 4194304 PRIMARY DATADG_0042 /dev/asm-disk48
676 Current.676.995708357 13 2 17 213923 4194304 PRIMARY DATADG_0017 /dev/asm-disk25
676 Current.676.995708357 14 2 27 213928 4194304 PRIMARY DATADG_0027 /dev/asm-disk34
676 Current.676.995708357 15 2 18 213921 4194304 PRIMARY DATADG_0018 /dev/asm-disk26
16 rows selected.
ASMCMD> mapextent '+DATADG/ANBOB/CONTROLFILE/current.676.995708357' 0
Disk_Num AU Extent_Size
6 3 1
ASMCMD> mapextent '+DATADG/ANBOB/CONTROLFILE/current.676.995708357' 1
Disk_Num AU Extent_Size
43 3 1
ASMCMD> mapau 2 43 3
File_Num Extent Extent_Set
676 1 1
ASMCMD>
— 计算control file 676 block 40#在哪个AU上
(block#) 40 * (confile file block size) 16k/ (_asm_stripewidth) 128k=5. 第1条带的第5个AU 上,第1个128k.
| AU | AU ext0 | AU ext1 | AU ext2 | AU ext3 | AU ext4 | AU ext5 | AU ext6 | AU ext7 |
| DISK.AU | 6.3 | 43.3 | 26.2 | 15.8 | 3.2 | 10.1 | 20.3 | 41.3 |
| strips size | 128k | 128k | 128k | 128k | 128k | 128k | 128k | 128k |
| ctl block# | 0-7 | 8-15 | 14-23 | 24-31 | 32-40 |
如果验证我们确认这个位置是确实是我们推算的值?dump block
SQL> select group_number,disk_number,path from v$asm_disk where disk_number=6 and group_number=2;
GROUP_NUMBER DISK_NUMBER PATH
------------ ----------- ------------------------------
2 6 /dev/asm-disk15
grid@anbob:~$dd if=/dev/asm-disk15 bs=4194304 skip=3 count=1 |dd bs=128k count=1 |dd bs=16384 count=1 |hexdump -C
00000000 00 c2 00 00 00 00 c0 ff 00 00 00 00 00 00 00 00 |................|
00000010 ea 76 00 00 00 40 00 00 2c 0d 00 00 7d 7c 7b 7a |.v...@..,...}|{z|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
grid@anbob:~$dd if=/dev/asm-disk15 bs=4194304 skip=3 count=1 |dd bs=128k count=1 |dd bs=16384 count=1 skip=7|hexdump -C
00000000 15 c2 00 00 07 00 00 00 00 00 00 00 00 00 01 04 |................|
00000010 ed 2c 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |.,..............|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
SQL> select group_number,disk_number,path from v$asm_disk where disk_number=3 and group_number=2;
GROUP_NUMBER DISK_NUMBER PATH
------------ ----------- ------------------------------
2 3 /dev/asm-disk12
grid@anbob:~$dd if=/dev/asm-disk12 bs=4194304 skip=2 count=1 |dd bs=128k count=1 |dd bs=16384 count=1 |hexdump -C
00000000 15 c2 00 00 20 00 00 00 00 00 00 00 00 00 01 04 |.... ...........|
00000010 ca 2c 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |.,..............|
grid@anbob:~$dd if=/dev/asm-disk12 bs=4194304 skip=2 count=1 |dd bs=128k count=1 |dd bs=16384 count=1 skip=7|hexdump -C
00000000 15 c2 00 00 27 00 00 00 9d 47 d8 3c ff ff 01 04 |....'....G.<....|
00000010 c1 e1 00 00 00 00 40 2b 04 f1 2a 00 00 00 00 00 |......@+..*.....|
00000020 0b 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 41 00 00 00 00 00 40 00 00 00 00 00 00 00 |..A.....@.......|
TIP:
block 的4-7字节是rdba, 转换成块号刚好是40#(0x27) block,因为是从0开始的。 这样也就确实了物理disk和具体位置。
查看DISK 性能
然后就可以根据ASM DISK查找映射的disk device. 用iostat查看IO性能
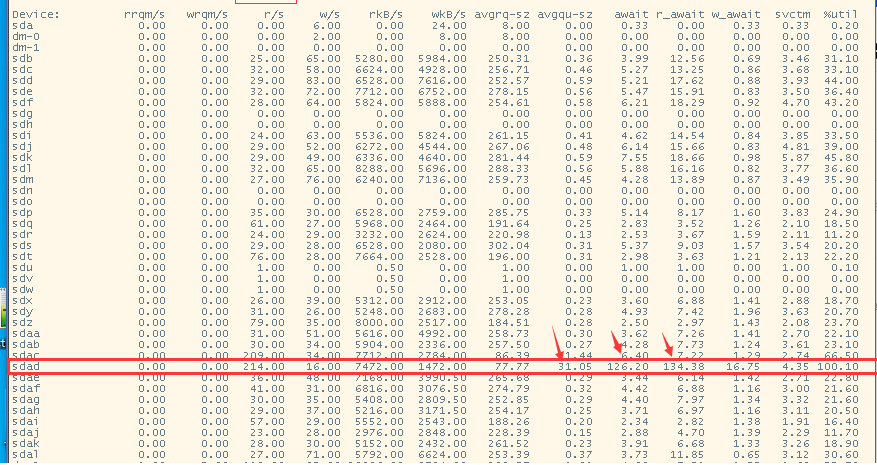
发现control file 40 block对应的磁盘当时read/s 214 w/s 16 应该是达到了单盘的最大iops, avgqu-size和awwait ,%util出现较高的值,确认该磁盘出现较高的瓶颈,有必要检查一下队列尝试,出现了较高的hot disk. 这个问题先记录到这里。
— enjoy —

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~


对不起,这篇文章暂时关闭评论。