Troubleshooting ORA-600 [kcrfw_search_blklctn: Dead loop] and more about NSA process
Format: ORA-600 [kcrfw_search_blklctn: Dead loop] [a] [b] [c] [d] [e], in Oracle Dataguard 11.2.0.3 RAC on AIX . This error will have no effect other than a small delay to the DataGuard redo translate.
Error output
ORA-00600: internal error code, arguments: [kcrfw_search_blklctn: Dead loop], [], [], [], [], [], [], [], [], [], [], []
Closing Redo Read Context
NSA2: Exception 600 encountered.. shutting down
NSA2: Doing a channel reset for next time around...
Trace file
Oracle Database 11g Enterprise Edition Release 11.2.0.3.0 - 64bit Production With the Partitioning, Real Application Clusters, Automatic Storage Management, OLAP, Data Mining and Real Application Testing options ORACLE_HOME = /oracle/app/oracle/product/11.2.0.3/dbhome_1 System name: AIX Node name: anbob2 Release: 1 Version: 7 Machine: 00F636EE4C00 Instance name: dbanbob2 Redo thread mounted by this instance: 2 Oracle process number: 59 Unix process pid: 3801622, image: oracle@anbob2 (NSA2) *** 2019-06-03 10:37:54.240 *** SESSION ID:(5547.1) 2019-06-03 10:37:54.240 *** CLIENT ID:() 2019-06-03 10:37:54.240 *** SERVICE NAME:(SYS$BACKGROUND) 2019-06-03 10:37:54.240 *** MODULE NAME:() 2019-06-03 10:37:54.240 *** ACTION NAME:() 2019-06-03 10:37:54.240 Dump continued from file: /oracle/app/oracle/diag/rdbms/stddbanbob/dbanbob2/trace/dbanbob2_nsa2_3801622.trc ORA-00600: internal error code, arguments: [kcrfw_search_blklctn: Dead loop], [], [], [], [], [], [], [], [], [], [], [] ----- SQL Statement (None) ----- Current SQL information unavailable - no cursor. ----- Call Stack Trace ----- kgeadse <-kgerinv_internal <-kgerinv <-kgeasnmierr <- kcrfw_search_blklctn <-kcrfr_read_memory <-kcrfr_read <- krsw_redo_push <-krsw_action_respond <-ksbabs <- ksbrdp <-opirip <-opidrv <-sou2o <-opimai_real <- ssthrdmain <-main
Root cause:
BUG 14582560 fixed in 12c(12.1.0.2, 12.2)
What is NSAn Process?
Starting with 11gR1, Oracle Data Guard asynchronous redo transport will read redo directly from the in-memory log buffer, provided that the requested redo blocks still reside in the log buffer, and have not been reused for subsequent redo generation. If the redo blocks are not available in the log buffer, Data Guard asynchronous redo transport will read the redo from the Online Redo Log (ORL). The main advantage of this change is to reduce the number of I/O calls issued to the ORL. in 10g and 11g R1 use LNS background process, start 11g R2 use NSA backgroup process.
Oracle externalized buffer hit ratios through the view x$logbuf_readhist .
BUFSIZE – Actual and estimated buffer sizes. CURRENT row is the configured log buffer row
RDMEMBLKS – Actual and estimated reads from the log buffer
RDDISKBLKS – Actual and estimated reads from the Online Redo Log files
HITRATE – Memory hit ratio for the corresponding buffer size. CURRENT (BUFINFO) is the line for present log buffer. Ratio is calculated by RDMEMBLKS/( RDMEMBLKS+ RDDISKBLKS). It is important that we keep the hit ratios close to 100% in a healthy performing data guard environment.
upgrading LOG_BUFFER to a higher value or make sure there is no network bottleneck between primary and standby. This may improve over all dataguard syncing performance.
11g R2 DG async transport:
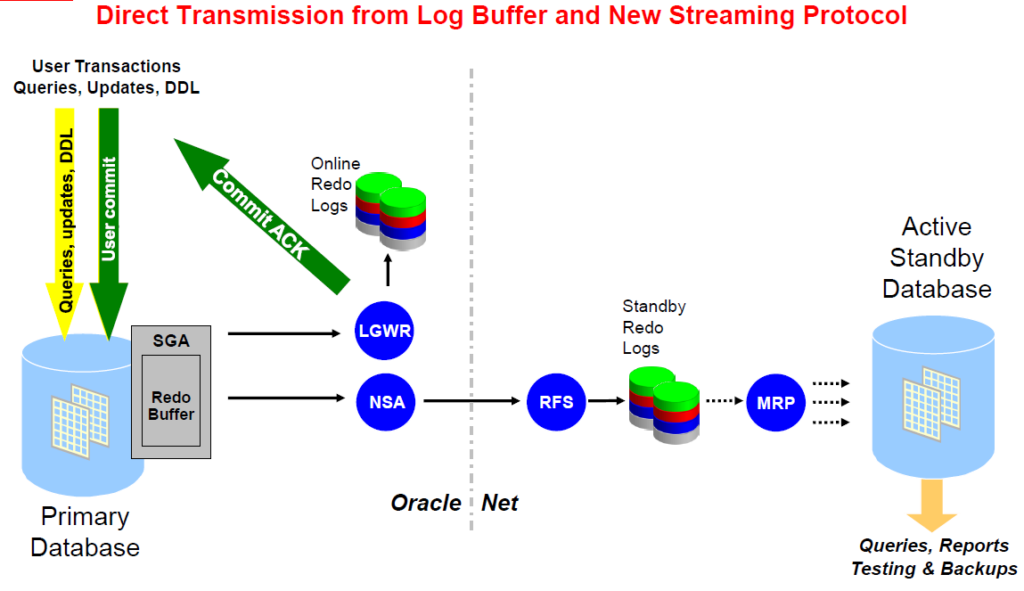
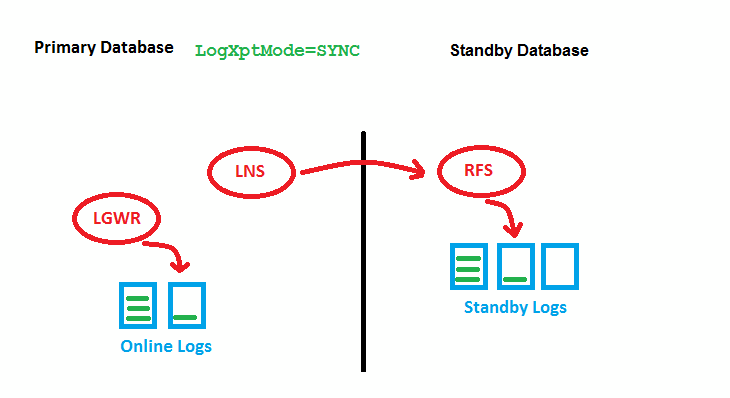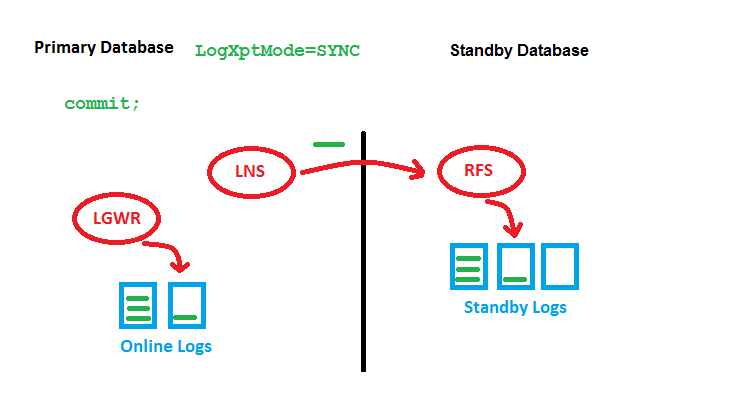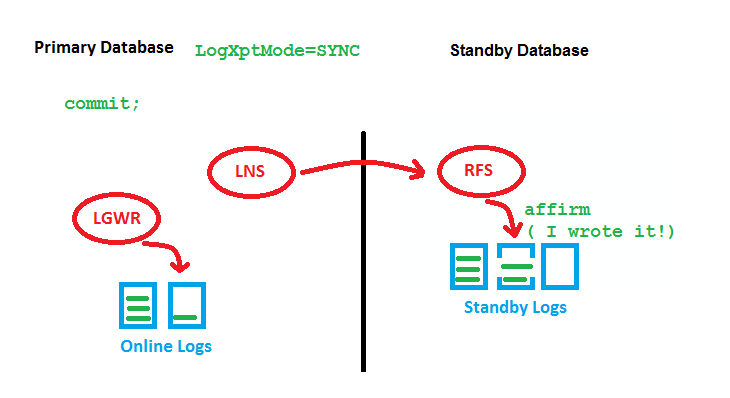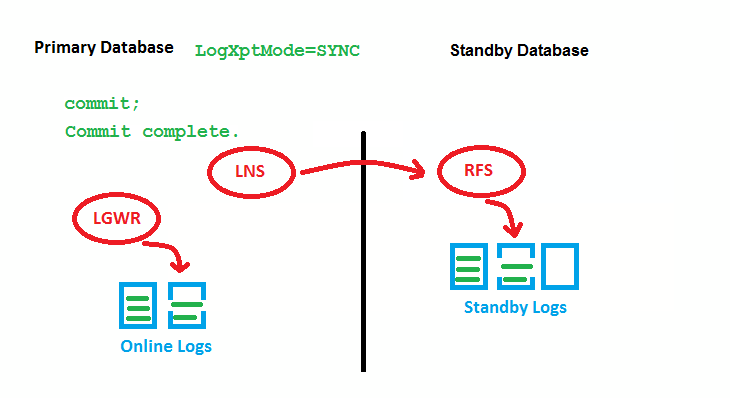
In a 10g oracle dataguard environment Log Network Server (LNS) process transports the redo from the primary to the standby site, until 11g R2 oracle introduce a new background process do that:
NSAn (Redo Transport NSA1 Process) is used on the primary database to ship redo data to the standby database when ASYNC mode is being used. There maybe multiple NSA processes such as NSA1 and NSA2.
NSSn (Redo Transport NSA1 Process) is also used on the primary database to ship redo data to the standby database. However, only when the SYNC mode is being used.
you will see new wait events for them:
‘SYNC Remote Write’ for all redo transport waits done by NSS processes
‘ASYNC Remote Write’ for all redo tranport waits done by NSA processes
Note that since 11gR2 the writing to online redo logs and to standby are done in parallel.
in 11.2.0.3 you maybe the below messages in the LGWR trace file :
NSS2 is not running anymore.
This message should appear only when log_archive_trace is nonzero.So when setting log_archive_trace = 0 those Messages should disappear. but due to Bug 19177843 The above messages can be seen even when the log_archive_trace is set to 0, fixed 12.2.
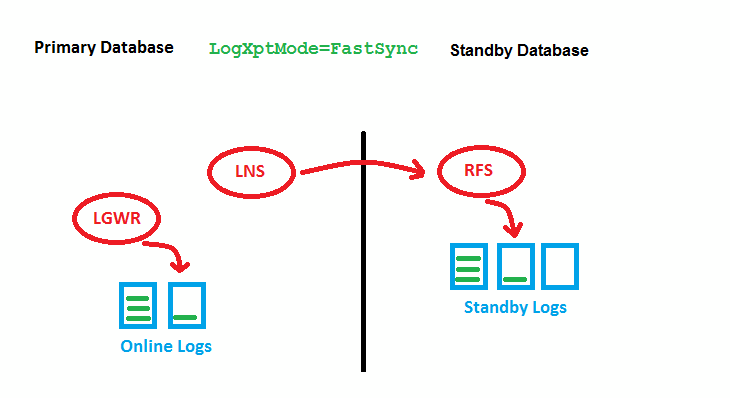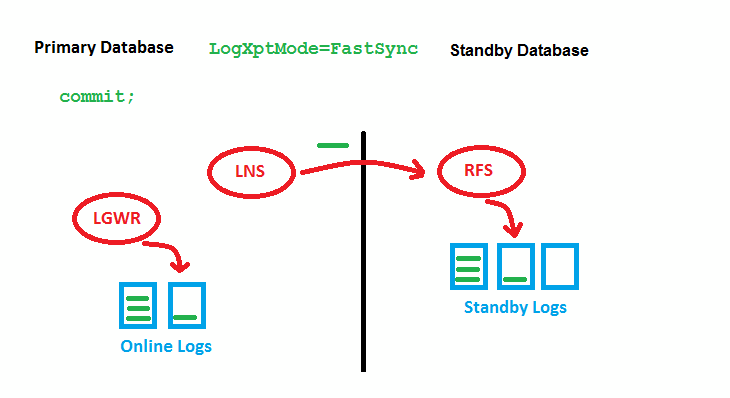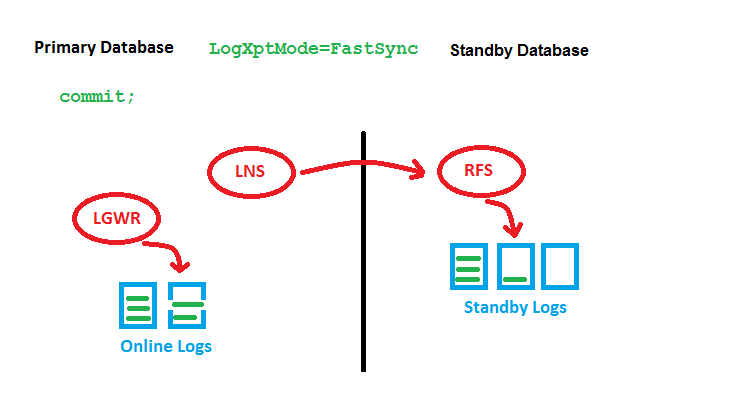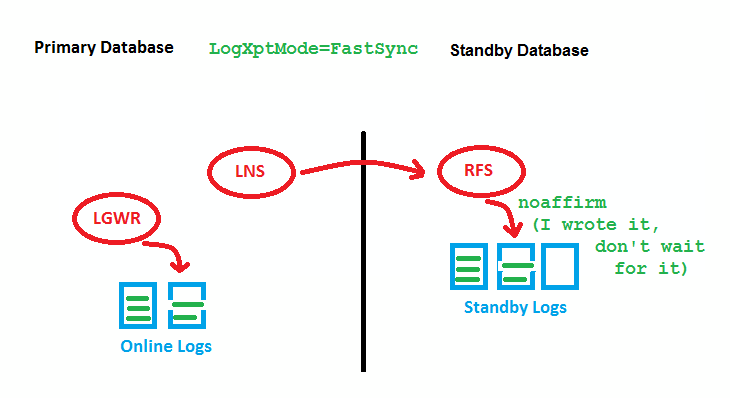
FASTSYNC is a new LogXptMode for Data Guard in 12c. It enables Maximum Availability protection mode at larger distances with less performance impact than LogXptMode SYNC has had before.
OLD SYNC (note: LNS 11g R2+ Replace by NSS)
NEW FASTSYNC (note: LNS 11g R2+ Replace by NSS)
References
FASTSYNC Redo Transport for Data Guard in #Oracle 12c
Franck Pachot’s Archive
MOS

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~


对不起,这篇文章暂时关闭评论。