《Oracle、Oceanbase、Kingbase、GaussDB、达梦数据库比较系列(二十七):子查询中的函数投影裁剪》 测试在inline subquery中包含函数列投影时裁剪或叫SLP(select list pruning) ,如果函数的Volate属性是volatile的影响,函数的不稳定性除了影响投影还有join 的view包含该函数时,影响谓词条件的推入等,最近在highgoDB遇到了一个SQL性能问题,其实所有pg系数据库如gaussdb,opengauss,kingbase等都存在。下面演示一下这个问题。
构建测试数据
-- pg
create table t1 as
select x as id, 'anbob'||x name,'03-07-2023'::timestamptz +(b::integer||' minute')::interval ctime
from generate_series(1,10000) as x(b);
create index idx_t1_ctime on t1(ctime);
create table t2(id int,ctime date,name text);
insert into t2 values(1,now(),'anbob');
insert into t2 values(2,now()+'1 day'::interval,'weejar');
insert into t2 values(3,'03-07-2023 01:00:00'::timestamptz,'anbob');
CREATE OR REPLACE FUNCTION f2(id integer)
returns bigint
language 'plpgsql'
as
$$
begin
return case when id>10 then 1 else 2 end;
end;
$$ ;
create or replace view v1
as
select id,name,ctime,f2(id) flag
from t1 where name<>'anbob100';
select * from t2 , v1
where t2.id=t2.id and t2.ctime >= to_date('2023-03-07 00:00:00', 'yyyy-mm-dd hh24:mi:ss')
AND t2.ctime < to_date('2023-03-08', 'yyyy-mm-dd hh24:mi:ss')
and v1.ctime>t2.ctime-('100 minute')::interval
and v1.ctime<t2.ctime
and (t2.name <> 'anbob1' or t2.name<>'weejar1');
-- oracle
create table t1 tablespace users as
select rownum id, 'anbob'||rownum name, to_date('03-07-2023','mm-dd-yyyy')+rownum/24/60 ctime
from dual connect by rownum<=10000;
create index idx_t1_ctime on t1(ctime);
create table t2(id int,ctime date,name varchar2(100)) tablespace users;
insert into t2 values(1,sysdate,'anbob');
insert into t2 values(2,sysdate+1,'weejar');
insert into t2 values(3,to_date('03-07-2023 01:00:00','mm-dd-yyyy hh24:mi:ss'),'anbob');
CREATE OR REPLACE FUNCTION f2(id integer)
return int
is
begin
return case when id>10 then 1 else 2 ;
end;
create or replace view v1
as
select id,name,ctime,f2(id) flag
from t1
where name<>'anbob100';
Note:
创建了两张表和一个view, 其中view中有一列是函数,注意这里的函数我仅为了演示使用的是常量,可以改稳定性,不排除如果是不能改稳定的函数时,这类问题就需要改SQL了。
先看oracle的执行计划
select * from t2 , v1
where t2.id=t2.id and t2.ctime >= to_date('2023-03-07 00:00:00', 'yyyy-mm-dd hh24:mi:ss')
AND t2.ctime < to_date('2023-03-08', 'yyyy-mm-dd hh24:mi:ss') and v1.ctime>t2.ctime-100/24/60
and v1.ctime>t2.ctime- 100 /24/60
and v1.ctime<t2.ctime
and (t2.name <> 'anbob1' or t2.name<>'weejar1');
Plan hash value: 1917871493
----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 28 | 1092 | 6 (0)| 00:00:01 |
|* 1 | FILTER | | | | | |
| 2 | NESTED LOOPS | | 28 | 1092 | 6 (0)| 00:00:01 |
| 3 | NESTED LOOPS | | 260 | 1092 | 6 (0)| 00:00:01 |
|* 4 | TABLE ACCESS FULL | T2 | 1 | 17 | 3 (0)| 00:00:01 |
|* 5 | INDEX RANGE SCAN | IDX_T1_CTIME | 260 | | 2 (0)| 00:00:01 |
|* 6 | TABLE ACCESS BY INDEX ROWID| T1 | 37 | 814 | 3 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter(TO_DATE('2023-03-08','yyyy-mm-dd hh24:mi:ss')>TO_DATE('2023-03-07 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
4 - filter(("T2"."NAME"<>'anbob1' OR "T2"."NAME"<>'weejar1') AND
"T2"."CTIME"<TO_DATE('2023-03-08','yyyy-mm-dd hh24:mi:ss') AND "T2"."ID" IS NOT NULL AND "T2"."CTIME">=TO_DATE(' 2023-03-07 00:00:00', 'syyyy-mm-dd hh24:mi:ss') AND
INTERNAL_FUNCTION("T2"."CTIME")-.0694444444444444444444444444444444444445<TO_DATE('2023-03-08','yyyy-mm-dd hh24:mi:ss'))
5 - access("CTIME">INTERNAL_FUNCTION("T2"."CTIME")-.0694444444444444444444444444444
444444445 AND "CTIME"<TO_DATE('2023-03-08','yyyy-mm-dd hh24:mi:ss'))
filter("CTIME"<"T2"."CTIME")
6 - filter("NAME"<>'anbob100')
Note:
#5 显示谓词已推到view v1,使用了ctime上的索引。
hint禁用oracle的特性观察一下
SQL> select /*+no_merge(v1)*/* from t2 , v1
where t2.id=t2.id and t2.ctime >= to_date('2023-03-07 00:00:00', 'yyyy-mm-dd hh24:mi:ss')
AND t2.ctime < to_date('2023-03-08', 'yyyy-mm-dd hh24:mi:ss') 4 and v1.ctime>t2.ctime-100/24/60
and v1.ctime>t2.ctime- 100 /24/60
and v1.ctime<t2.ctime
and (t2.name <> 'anbob1' or t2.name<>'weejar1');
SQL> @x2
PLAN_TABLE_OUTPUT
-----------------------------------------------------------------------------------------------------------------------------------
Plan hash value: 2510977736
-------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 28 | 2128 | 7 (0)| 00:00:01 |
| 1 | NESTED LOOPS | | 28 | 2128 | 7 (0)| 00:00:01 |
|* 2 | TABLE ACCESS FULL | T2 | 1 | 17 | 3 (0)| 00:00:01 |
| 3 | VIEW PUSHED PREDICATE | V1 | 1 | 59 | 4 (0)| 00:00:01 |
|* 4 | FILTER | | | | | |
|* 5 | TABLE ACCESS BY INDEX ROWID BATCHED| T1 | 4 | 88 | 4 (0)| 00:00:01 |
|* 6 | INDEX RANGE SCAN | IDX_T1_CTIME | 25 | | 3 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter(("T2"."NAME"<>'anbob1' OR "T2"."NAME"<>'weejar1') AND
"T2"."CTIME"<TO_DATE('2023-03-08','yyyy-mm-dd hh24:mi:ss') AND "T2"."ID" IS NOT NULL AND "T2"."CTIME">=TO_DATE(' 2023-03-07 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
4 - filter("T2"."CTIME">INTERNAL_FUNCTION("T2"."CTIME")-.06944444444444444444444444444444444
44445 AND INTERNAL_FUNCTION("T2"."CTIME")-.0694444444444444444444444444444444444445<TO_DATE('20 23-03-08','yyyy-mm-dd hh24:mi:ss') AND TO_DATE('2023-03-08','yyyy-mm-dd hh24:mi:ss')>TO_DATE('
2023-03-07 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
5 - filter("NAME"<>'anbob100')
6 - access("CTIME">INTERNAL_FUNCTION("T2"."CTIME")-.0694444444444444444444444444444444444445
AND "CTIME"<TO_DATE('2023-03-08','yyyy-mm-dd hh24:mi:ss'))
filter("CTIME"<"T2"."CTIME") select /*+no_merge(v1) NO_PUSH_PRED(v1)*/* from t2 , v1 where t2.id=t2.id and t2.ctime >= to_date('2023-03-07 00:00:00', 'yyyy-mm-dd hh24:mi:ss')
AND t2.ctime < to_date('2023-03-08', 'yyyy-mm-dd hh24:mi:ss') and v1.ctime>t2.ctime-100/24/60
and v1.ctime 'anbob1' or t2.name<>'weejar1');
SQL> @x2
PLAN_TABLE_OUTPUT
-----------------------------------------------------------------------------------------------------------------------------
Plan hash value: 1639856690
-------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 28 | 2128 | 14 (0)| 00:00:01 |
| 1 | NESTED LOOPS | | 28 | 2128 | 14 (0)| 00:00:01 |
|* 2 | TABLE ACCESS FULL | T2 | 1 | 17 | 3 (0)| 00:00:01 |
|* 3 | VIEW | V1 | 37 | 2183 | 11 (0)| 00:00:01 |
|* 4 | FILTER | | | | | |
|* 5 | TABLE ACCESS BY INDEX ROWID BATCHED| T1 | 1439 | 31658 | 11 (0)| 00:00:01 |
|* 6 | INDEX RANGE SCAN | IDX_T1_CTIME | 1439 | | 5 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter(("T2"."NAME"<>'anbob1' OR "T2"."NAME"<>'weejar1') AND
"T2"."CTIME"<TO_DATE('2023-03-08','yyyy-mm-dd hh24:mi:ss') AND "T2"."ID" IS NOT NULL AND "T2"."CTIME">=TO_DATE(' 2023-03-07 00:00:00', 'syyyy-mm-dd hh24:mi:ss') AND
INTERNAL_FUNCTION("T2"."CTIME")-.0694444444444444444444444444444444444445<TO_DATE('2023-03-08',
'yyyy-mm-dd hh24:mi:ss'))
3 - filter("V1"."CTIME"<"T2"."CTIME" AND "V1"."CTIME">INTERNAL_FUNCTION("T2"."CTIME")-.06944
44444444444444444444444444444444445)
4 - filter(TO_DATE('2023-03-08','yyyy-mm-dd hh24:mi:ss')>TO_DATE(' 2023-03-07 00:00:00',
'syyyy-mm-dd hh24:mi:ss'))
5 - filter("NAME"<>'anbob100')
6 - access("CTIME"<TO_DATE('2023-03-08','yyyy-mm-dd hh24:mi:ss'))
28 rows selected.
达梦
explain
select * from t2 , v1
where t2.id=t2.id and t2.ctime >= to_date('2023-03-07 00:00:00', 'yyyy-mm-dd hh24:mi:ss')
AND t2.ctime < to_date('2023-03-08', 'yyyy-mm-dd hh24:mi:ss') and v1.ctime>t2.ctime-100/24/60
and v1.ctime and v1.ctime>t2.ctime- 100 /24/60
and v1.ctime<t2.ctime
and (t2.name <> 'anbob1' or t2.name<>'weejar1');
1 #NSET2: [1, 375, 134]
2 #PRJT2: [1, 375, 134]; exp_num(7), is_atom(FALSE)
3 #SLCT2: [1, 375, 134]; T1.NAME <> 'anbob100'
4 #NEST LOOP INDEX JOIN2: [1, 375, 134]
5 #SLCT2: [1, 1, 65]; (NOT(T2.NAME IS NULL) AND NOT(T2.ID IS NULL) AND T2.CTIME >= var2 AND T2.CTIME < var4)
6 #CSCN2: [1, 3, 65]; INDEX33708464(T2); btr_scan(1)
7 #BLKUP2: [1, 375, 13]; IDX_T1_CTIME(T1)
8 #SSEK2: [1, 375, 13]; scan_type(ASC), IDX_T1_CTIME(T1), scan_range(exp_cast(T2.CTIME-exp_cast(100/24/60)),exp_cast(T2.CTIME))
used time: 30.703(ms). Execute id is 0.
Highgo V9(pg14)
SET track_io_timing = TRUE;
RESET enable_hashjoin;
RESET enable_sort;
explain (analyze,verbose)
select * from t2 , v1
where t2.id=t2.id and t2.ctime >= to_date('2023-03-07 00:00:00', 'yyyy-mm-dd hh24:mi:ss')
AND t2.ctime < to_date('2023-03-08', 'yyyy-mm-dd hh24:mi:ss') and v1.ctime>t2.ctime-('100 minute')::interval
and v1.ctime >t2.ctime-('100 minute')::interval
and v1.ctime<t2.ctime
and (t2.name <> 'anbob1' or t2.name<>'weejar1');
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
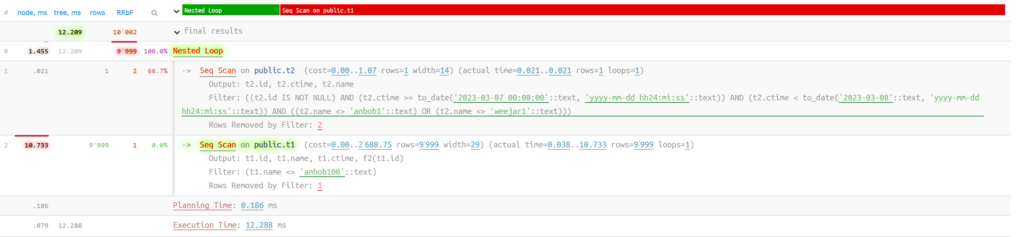
Nested Loop (cost=0.00..2964.80 rows=1111 width=43) (actual time=12.208..12.209 rows=0 loops=1)
Output: t2.id, t2.ctime, t2.name, t1.id, t1.name, t1.ctime, (f2(t1.id))
Join Filter: ((t1.ctime < t2.ctime) AND (t1.ctime > (t2.ctime - '01:40:00'::interval)))
Rows Removed by Join Filter: 9999
-> Seq Scan on public.t2 (cost=0.00..1.07 rows=1 width=14) (actual time=0.021..0.021 rows=1 loops=1)
Output: t2.id, t2.ctime, t2.name
Filter: ((t2.id IS NOT NULL) AND (t2.ctime >= to_date('2023-03-07 00:00:00'::text, 'yyyy-mm-dd hh24:mi:ss'::text)) AND (t2.ctime < to_date('2023-03-08'::text, 'yyyy-mm-dd hh24:mi:ss'::text)) AND ((t
2.name <> 'anbob1'::text) OR (t2.name <> 'weejar1'::text)))
Rows Removed by Filter: 2
-> Seq Scan on public.t1 (cost=0.00..2688.75 rows=9999 width=29) (actual time=0.038..10.733 rows=9999 loops=1)
Output: t1.id, t1.name, t1.ctime, f2(t1.id)
Filter: (t1.name <> 'anbob100'::text)
Rows Removed by Filter: 1
Planning Time: 0.186 ms
Execution Time: 12.288 ms
(14 rows)
Note:
这里t1表使用的全表扫seq scan. 使用了nested loop join最外层 join里过滤时间, 而t1表的大小就决定了SQL的运行时间,在生产上刚好我们的表是个大分区表有几亿条记录,运行时间要等十几分钟。开始以为是function cost影响,修改后function cost并不会影响v1的访问路径。
修改函数volatile到immutable
alter function f2 immutable;
SET track_io_timing = TRUE;
explain (analyze,verbose)
select * from t2 , v1
where t2.id=t2.id and t2.ctime >= to_date('2023-03-07 00:00:00', 'yyyy-mm-dd hh24:mi:ss')
AND t2.ctime < to_date('2023-03-08', 'yyyy-mm-dd hh24:mi:ss') and v1.ctime>t2.ctime-('100 minute')::interval
and v1.ctime>t2.ctime-('100 minute')::interval
and v1.ctime<t2.ctime
and (t2.name <> 'anbob1' or t2.name<>'weejar1');
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
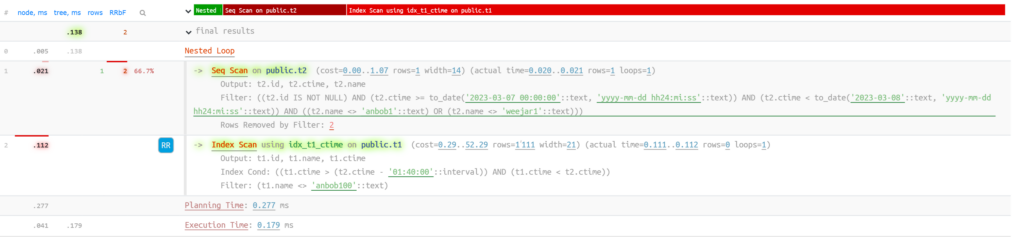
Nested Loop (cost=0.29..342.22 rows=1111 width=43) (actual time=0.055..0.056 rows=0 loops=1)
Output: t2.id, t2.ctime, t2.name, t1.id, t1.name, t1.ctime, f2(t1.id)
-> Seq Scan on public.t2 (cost=0.00..1.07 rows=1 width=14) (actual time=0.024..0.025 rows=1 loops=1)
Output: t2.id, t2.ctime, t2.name
Filter: ((t2.id IS NOT NULL) AND (t2.ctime >= to_date('2023-03-07 00:00:00'::text, 'yyyy-mm-dd hh24:mi:ss'::text)) AND (t2.ctime < to_date('2023-03-08'::text, 'yyyy-mm-dd hh24:mi:ss'::text)) AND ((t
2.name <> 'anbob1'::text) OR (t2.name <> 'weejar1'::text)))
Rows Removed by Filter: 2
-> Index Scan using idx_t1_ctime on public.t1 (cost=0.29..52.29 rows=1111 width=21) (actual time=0.026..0.026 rows=0 loops=1)
Output: t1.id, t1.name, t1.ctime
Index Cond: ((t1.ctime > (t2.ctime - '01:40:00'::interval)) AND (t1.ctime < t2.ctime))
Filter: (t1.name <> 'anbob100'::text)
Planning Time: 0.252 ms
Execution Time: 0.102 ms
(12 rows)
Note:
这里ctime条件pushdown到了v1 view中,在访问T1时,使用上了索引,并且也做了投影裁剪,执行效率明显提升,而生产环境上的案例SQL直接从10几分钟提到秒级。 这里索引访问显示有Index Cond和Filter两个算子,目标是一样的,但是实现方式完全不同。Index Cond 用于从index索引中查找行位置的条件,Postgres 使用索引的结构化特性快速跳转到它要查找的行。不同的索引类型使用不同的策略。而在 “Filter” 中,根据row行的值检索并丢弃行。因此,您可以在同一操作中找到 “Index Cond” 和 “Filter”。 索引改为volatile,执行计划同immutable.
执行计划美化后,看起来更直观
不能推进的原因
当开源数据库找不到相关官方文档,查找源代码是个不错的方向 https://github.com/postgres/postgres/blob/master/src/backend/optimizer/path/allpaths.c
查找相关set_subquery_pathlist 里面的 subquery_is_pushdown_safe() 和 qual_is_pushdown_safe()函数.和contain_volatile_functions()
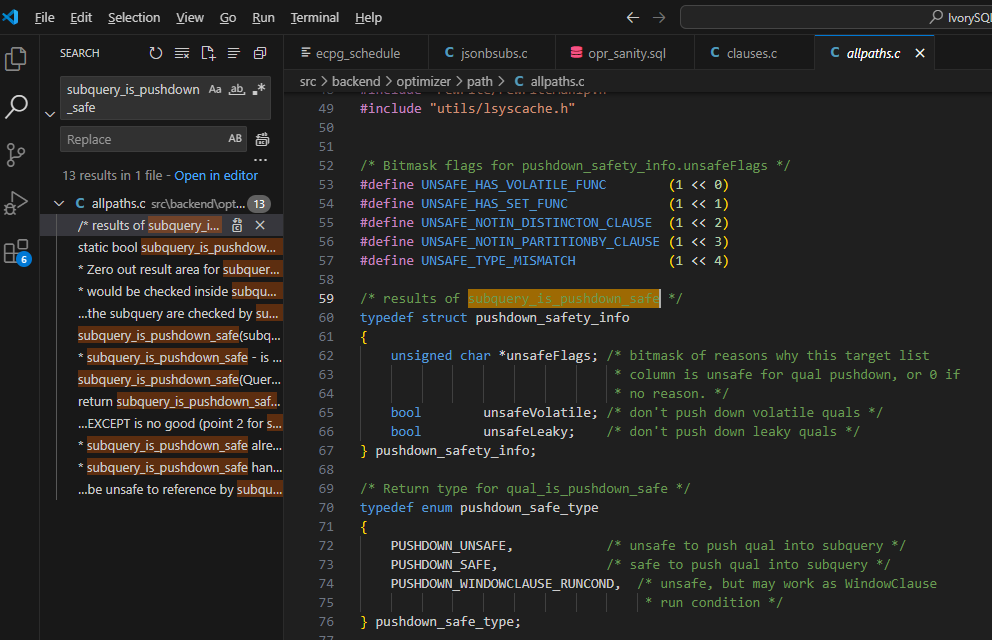
/* results of subquery_is_pushdown_safe */ typedef struct pushdown_safety_info { unsigned char *unsafeFlags; /* bitmask of reasons why this target list * column is unsafe for qual pushdown, or 0 if * no reason. */ bool unsafeVolatile; /* don't push down volatile quals */ bool unsafeLeaky; /* don't push down leaky quals */ } pushdown_safety_info; /* * check_output_expressions - check subquery's output expressions for safety * * There are several cases in which it's unsafe to push down an upper-level * qual if it references a particular output column of a subquery. We check * each output column of the subquery and set flags in unsafeFlags[k] when we * see that column is unsafe for a pushed-down qual to reference. The * conditions checked here are: * * 1. We must not push down any quals that refer to subselect outputs that * return sets, else we'd introduce functions-returning-sets into the * subquery's WHERE/HAVING quals. * * 2. We must not push down any quals that refer to subselect outputs that * contain volatile functions, for fear of introducing strange results due * to multiple evaluation of a volatile function. * * 3. If the subquery uses DISTINCT ON, we must not push down any quals that * refer to non-DISTINCT output columns, because that could change the set * of rows returned. (This condition is vacuous for DISTINCT, because then * there are no non-DISTINCT output columns, so we needn't check. Note that * subquery_is_pushdown_safe already reported that we can't use volatile * quals if there's DISTINCT or DISTINCT ON.) * * 4. If the subquery has any window functions, we must not push down quals * that reference any output columns that are not listed in all the subquery's * window PARTITION BY clauses. We can push down quals that use only * partitioning columns because they should succeed or fail identically for * every row of any one window partition, and totally excluding some * partitions will not change a window function's results for remaining * partitions. (Again, this also requires nonvolatile quals, but * subquery_is_pushdown_safe handles that.). Subquery columns marked as * unsafe for this reason can still have WindowClause run conditions pushed * down. */ /* * set_subquery_pathlist * Generate SubqueryScan access paths for a subquery RTE * * We don't currently support generating parameterized paths for subqueries * by pushing join clauses down into them; it seems too expensive to re-plan * the subquery multiple times to consider different alternatives. * (XXX that could stand to be reconsidered, now that we use Paths.) * So the paths made here will be parameterized if the subquery contains * LATERAL references, otherwise not. As long as that's true, there's no need * for a separate set_subquery_size phase: just make the paths right away. */ /***************************************************************************** * PUSHING QUALS DOWN INTO SUBQUERIES *****************************************************************************/ /* * subquery_is_pushdown_safe - is a subquery safe for pushing down quals? * * subquery is the particular component query being checked. topquery * is the top component of a set-operations tree (the same Query if no * set-op is involved). * * Conditions checked here: * * 1. If the subquery has a LIMIT clause, we must not push down any quals, * since that could change the set of rows returned. * * 2. If the subquery contains EXCEPT or EXCEPT ALL set ops we cannot push * quals into it, because that could change the results. * * 3. If the subquery uses DISTINCT, we cannot push volatile quals into it. * This is because upper-level quals should semantically be evaluated only * once per distinct row, not once per original row, and if the qual is * volatile then extra evaluations could change the results. (This issue * does not apply to other forms of aggregation such as GROUP BY, because * when those are present we push into HAVING not WHERE, so that the quals * are still applied after aggregation.) * * 4. If the subquery contains window functions, we cannot push volatile quals * into it. The issue here is a bit different from DISTINCT: a volatile qual * might succeed for some rows of a window partition and fail for others, * thereby changing the partition contents and thus the window functions' * results for rows that remain. * * 5. If the subquery contains any set-returning functions in its targetlist, * we cannot push volatile quals into it. That would push them below the SRFs * and thereby change the number of times they are evaluated. Also, a * volatile qual could succeed for some SRF output rows and fail for others, * a behavior that cannot occur if it's evaluated before SRF expansion. * * 6. If the subquery has nonempty grouping sets, we cannot push down any * quals. The concern here is that a qual referencing a "constant" grouping * column could get constant-folded, which would be improper because the value * is potentially nullable by grouping-set expansion. This restriction could * be removed if we had a parsetree representation that shows that such * grouping columns are not really constant. (There are other ideas that * could be used to relax this restriction, but that's the approach most * likely to get taken in the future. Note that there's not much to be gained * so long as subquery_planner can't move HAVING clauses to WHERE within such * a subquery.) * * In addition, we make several checks on the subquery's output columns to see * if it is safe to reference them in pushed-down quals. If output column k * is found to be unsafe to reference, we set the reason for that inside * safetyInfo->unsafeFlags[k], but we don't reject the subquery overall since * column k might not be referenced by some/all quals. The unsafeFlags[] * array will be consulted later by qual_is_pushdown_safe(). It's better to * do it this way than to make the checks directly in qual_is_pushdown_safe(), * because when the subquery involves set operations we have to check the * output expressions in each arm of the set op. * * Note: pushing quals into a DISTINCT subquery is theoretically dubious: * we're effectively assuming that the quals cannot distinguish values that * the DISTINCT's equality operator sees as equal, yet there are many * counterexamples to that assumption. However use of such a qual with a * DISTINCT subquery would be unsafe anyway, since there's no guarantee which * "equal" value will be chosen as the output value by the DISTINCT operation. * So we don't worry too much about that. Another objection is that if the * qual is expensive to evaluate, running it for each original row might cost * more than we save by eliminating rows before the DISTINCT step. But it * would be very hard to estimate that at this stage, and in practice pushdown * seldom seems to make things worse, so we ignore that problem too. * * Note: likewise, pushing quals into a subquery with window functions is a * bit dubious: the quals might remove some rows of a window partition while * leaving others, causing changes in the window functions' results for the * surviving rows. We insist that such a qual reference only partitioning * columns, but again that only protects us if the qual does not distinguish * values that the partitioning equality operator sees as equal. The risks * here are perhaps larger than for DISTINCT, since no de-duplication of rows * occurs and thus there is no theoretical problem with such a qual. But * we'll do this anyway because the potential performance benefits are very * large, and we've seen no field complaints about the longstanding comparable * behavior with DISTINCT. */ /* * If there are any restriction clauses that have been attached to the * subquery relation, consider pushing them down to become WHERE or HAVING * quals of the subquery itself. This transformation is useful because it * may allow us to generate a better plan for the subquery than evaluating * all the subquery output rows and then filtering them. * * There are several cases where we cannot push down clauses. Restrictions * involving the subquery are checked by subquery_is_pushdown_safe(). * Restrictions on individual clauses are checked by * qual_is_pushdown_safe(). Also, we don't want to push down * pseudoconstant clauses; better to have the gating node above the * subquery. * * Non-pushed-down clauses will get evaluated as qpquals of the * SubqueryScan node. * * XXX Are there any cases where we want to make a policy decision not to * push down a pushable qual, because it'd result in a worse plan? */ /* * qual_is_pushdown_safe - is a particular rinfo safe to push down? * * rinfo is a restriction clause applying to the given subquery (whose RTE * has index rti in the parent query). * * Conditions checked here: * * 1. rinfo's clause must not contain any SubPlans (mainly because it's * unclear that it will work correctly: SubLinks will already have been * transformed into SubPlans in the qual, but not in the subquery). Note that * SubLinks that transform to initplans are safe, and will be accepted here * because what we'll see in the qual is just a Param referencing the initplan * output. * * 2. If unsafeVolatile is set, rinfo's clause must not contain any volatile * functions. * * 3. If unsafeLeaky is set, rinfo's clause must not contain any leaky * functions that are passed Var nodes, and therefore might reveal values from * the subquery as side effects. * * 4. rinfo's clause must not refer to the whole-row output of the subquery * (since there is no easy way to name that within the subquery itself). * * 5. rinfo's clause must not refer to any subquery output columns that were * found to be unsafe to reference by subquery_is_pushdown_safe(). */ /* * Don't pull up a subquery that has any volatile functions in its * targetlist. Otherwise we might introduce multiple evaluations of these * functions, if they get copied to multiple places in the upper query, * leading to surprising results. (Note: the PlaceHolderVar mechanism * doesn't quite guarantee single evaluation; else we could pull up anyway * and just wrap such items in PlaceHolderVars ...) */ if (contain_volatile_functions((Node *) subquery->targetList)) return false; return true;
Postgresql在处理view中的volatile 函数时,对predicat push-down 处理逻辑:
1, safe安全检查subquery_is_pushdown_safe
如果包含limit, EXCEPT or EXCEPT ALL ,distinct, window-function 集合返回函数,表示volatile 函数可能不安全
2,具体的谓词检查
在qual_is_pushdown_safe函数中会检查具体的谓词是否安全
如果unsafevolatile被标记为true, 谓词中包含volatile函数, 输出列检查check_output_expressions()如果输出列有volitile函数,无法pushdown。
小结:
因为volatile函数每次执行调用可能返回不同的结果,可以导致 结果不一致,如果视图中的volatile函数在输出列中,相关的谓词不会被下推。
感叹postgresql源代码中的注释写的很清楚,如果把这些训练专业的大模型,那回答Postgresql问题就一个专家。