故障诊断 Oceanbase “ORA-00600: internal error code, arguments: -4013, No memory or reach tenant memory limit” 特烦恼
昨天Oceanbase V4.3发布会,因为工作忙原因无法现场参加学习,近几年国产数据库在快速迭代,无论是bug修复还是功能引进,OB的版本的迭代速度和客户发展速度是值得肯定,尤其在XC的走的最快的金融行业,从分布式到集中式,行列混合存储引擎,混合负载模式支持,oracle与mysql等多模,今年的向量功能,朝着all in one (OB) 的方向演进,这似乎也是oracle 数据库的技术路线,只是oracle是从集中式向分布式。
但是就在OB发布会的同一天,我们另一批人因为新上的Oceanbase在焦急的处理着故障,一个租户的内存耗尽,然后级联的活动会话增加,CPU耗尽到重启。 根因还是无人能给个明确答复,解决方案自然是重启大法和“人”给我盯紧了。这里我发现现象,首先是现场能力要么有限,要么是数据库的诊断手段有限,要么大家都不愿意承认自己有问题,包括应用、数据库、部门领导,所以就没人主推。其次是想分析公开文档欠缺,全网只有官方在线文档一条简单的表述;再次是如果按那篇公开文档所描述是因为DB设计问题,在新版本已解决,这也暴露出在版本不成熟快速迭代期,生产版本的选择方案问题,上线周期2年,拉起所有版本(旧版本)是否还合理?
“如果只允许一种声音存在,那么,唯一存在的那个声音就是谎言。” –柏拉图
环境 oceanbase for oracle V 3.2.4 BP5
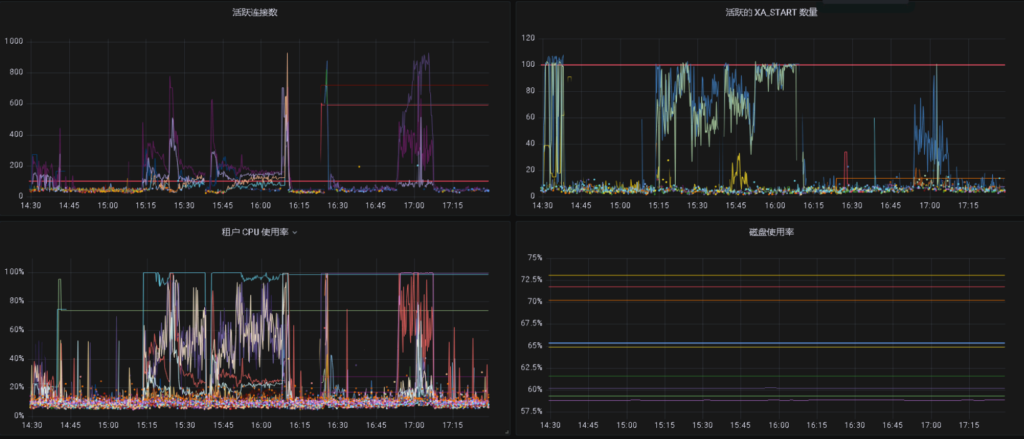
CPU和ACTIVE session暴增,应急先尝试SQL 限流

SQL限流失败,提示ORA-00600: internal error code, arguments: -4013, No memory or reach tenant memory limit, 查看内存使用率。
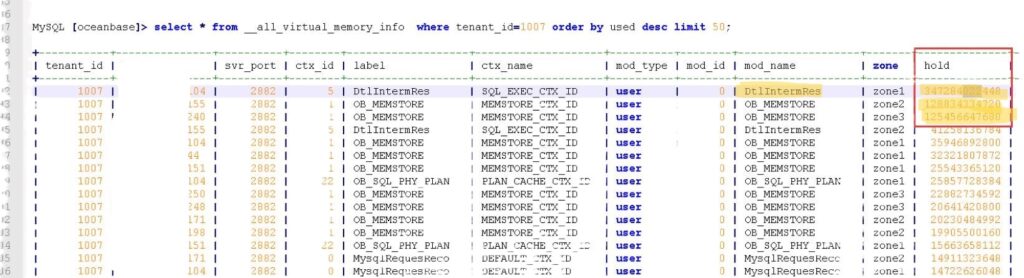
发现当前一般租户使用最高的是SQL_EXEC_CTX_ID, label和mod_name为DtlIntermRes, hold内存区近340GB。
内存相关内部表
| 视图 | 描述 | |
|---|---|---|
| __all_virtual_tenant_ctx_memory_info | context 级别的统计信息(context 是面向开发者的概念),它是 2M 粒度的统计。 | |
| __all_virtual_memory_info | OBServer 内存标签的统计信息。 | |
| __all_virtual_tenant_memstore_info | memstore 统计信息。 | |
| __all_virtual_kvcache_info | kvcache 统计信息。 | |
分析日志关键字
而分布式数据库分析最麻烦的就是分析日志,一个集群一个小时900G的日志,如何识别关键字才能减少分析工作量,接下来查看observer.log中关键字“ret=-4013”, 像案例1日志中的模块是“ERROR [SQL.REWRITE]”阶段的ob_query_range.cpp ,文档说是SqlExecutor 或 CostBasedRewrite模块(可以通过__all_virtual_memory_info.mod_name确认),解决是修改了配置项 range_optimizer_max_mem_size 来限制 range 抽取时的内存使用,或增加 NO_REWRITE Hint 禁止 SQL 重写来进行规避。而案例2是一段memleak的信息因软件bug. 不过除了重启应急外,看不明白“hint 走主表”是什么意思 。不过一般OB会定期在日志中记录内存状态,可以 egrep “^[MMORY]” observer.log关键字过滤或 egrep “^[MMORY]%SQL_EXEC_CTX_ID” observer.log, 再根据事务号“tid”值,为关键字继续查找对应的trace_id ,再继续查看SQL 文本。 其它一些日志关键字如 fail to alloc memory 或 allocate memory fail . 也可以通过关键词 OOPS 确定内存爆的类型。
而本案例的SQL_EXEC_CTX_ID占用这么大的内存,势必会挤占MEMSTORE的内存区, 《Oceanbase Memstore 使用分析》记录过统计memstore的方法, 而memstore减少,为了防止出现ERROR 4030 (HY000): OB-4030:Over tenant memory limitsmemstore内存超限,不确认是不是会触发memstore限流,如参数writing_throttling_trigger_percentage、writing_throttling_maximum_duration,增加 Query 的运行时间(response time),从而降低外部的写入速度,而影响cpu使用率。 这些需要在问题发生时确认,当然也可以当时从长事务活动会话查找当时的SQL关连 gv$sql_audit,查当内存使用使用较大的SQL(REQUEST_MEMORY_USED), kill session并通知应用整改。
memleak分析
可以使用oceanbase的leak mode event开启捕捉DtlIntermRes内存堆栈。
登录sys租户 -- 开启捕捉 obclient [oceanbase]> alter system set leak_mod_to_check='SqlExecutor'; --查看内存使用较高的堆栈地址 obclient [oceanbase]> SELECT * FROM oceanbase.__all_virtual_mem_leak_checker_info ORDER BY alloc_count DESC limit 10; -- 转换地址为函数 [root@ob1 ~]# addr2line -pCfe /home/admin/oceanbase/bin/observer [__all_virtual_mem_leak_checker_info.back_trace地址] oceanbase::common::lbt(char*, int) at ./build_rpm/deps/oblib/src/lib/./deps/oblib/src/lib/utility/ob_backtrace.cpp:136 oceanbase::common::ObMemLeakChecker::on_alloc(oceanbase::lib::AObject&) at ??:? oceanbase::lib::ObMallocAllocator::alloc(long, oceanbase::lib::ObMemAttr const&) at ./build_rpm/deps/oblib/src/lib/./deps/oblib/src/lib/alloc/ob_malloc_allocator.cpp:125 oceanbase::common::ob_malloc(long, oceanbase::lib::ObMemAttr const&) at ./build_rpm/src/sql/./deps/oblib/src/lib/allocator/ob_malloc.h:53 oceanbase::sql::dtl::ObDTLIntermResultManager::process_interm_result_inner(oceanbase::sql::dtl::ObDtlLinkedBuffer&, oceanbase::sql::dtl::ObDTLIntermResultKey&, long, long, long, bool, bool, long&) at ./build_rpm/src/sql/./src/sql/dtl/ob_dtl_interm_result_manager.cpp:495 oceanbase::sql::dtl::ObDTLIntermResultManager::process_interm_result(oceanbase::sql::dtl::ObDtlLinkedBuffer*, long) at ??:? oceanbase::sql::dtl::ObDtlSendMessageP::process_msg(oceanbase::sql::dtl::ObDtlRpcDataResponse&, oceanbase::sql::dtl::ObDtlSendArgs&) at ./build_rpm/src/sql/./src/sql/dtl/ob_dtl_rpc_processor.cpp:50 oceanbase::sql::dtl::ObDtlSendMessageP::process() at ./build_rpm/src/sql/./src/sql/dtl/ob_dtl_rpc_processor.cpp:41 oceanbase::obrpc::ObRpcProcessorBase::run() at ./build_rpm/deps/oblib/src/rpc/./deps/oblib/src/rpc/obrpc/ob_rpc_processor_base.cpp:82 oceanbase::omt::ObWorkerProcessor::process_one(oceanbase::rpc::ObRequest&) at ./build_rpm/src/observer/./src/observer/omt/ob_worker_processor.cpp:76 oceanbase::omt::ObWorkerProcessor::process(oceanbase::rpc::ObRequest&) at ./build_rpm/src/observer/./src/observer/omt/ob_worker_processor.cpp:147 oceanbase::omt::ObThWorker::process_request(oceanbase::rpc::ObRequest&) at ./build_rpm/src/observer/./src/observer/omt/ob_th_worker.cpp:311 oceanbase::omt::ObThWorker::worker(long&, long&, int&) at ??:? non-virtual thunk to oceanbase::omt::ObThWorker::run(long) at ??:? operator() at ./build_rpm/deps/oblib/src/lib/./deps/oblib/src/lib/coro/co_user_thread.cpp:234 eeentry(boost::context::detail::transfer_t) at ./build_rpm/deps/oblib/src/lib/./deps/oblib/src/lib/coro/co_user_thread.cpp:44
什么是DTL
OceanBase 数据库将数据传输封装成了叫做 DTL(Data Transfer layer)的模块,可以通过 SHOW PARAMETERS 来查找相关参数的
obclient> SHOW PARAMETERS LIKE '%dtl%'\G
*************************** 1. row ***************************
zone: zone1
svr_type: observer
svr_ip: 172.xx.xxx.xxx
svr_port: 2882
name: dtl_buffer_size
data_type: CAPACITY
value: 64K
info: to be removed
section: OBSERVER
scope: CLUSTER
source: DEFAULT
edit_level: DYNAMIC_EFFECTIVE
1 row in set
似乎只有一个参数 dtl_buffer_size, 但是它是控制 EXCHANGE 算子之间(即Transmit 和 Receive 之间)发送数据时,每次发送数据的 Buffer 的大小(用于设置 SQL 数据传输模块使用的缓存大小)。可以查询 V$OB_DTL_INTERM_RESULT_MONITOR展示 DTL 中间结果管理器的监控信息,查看哪个SQL占用内存较高(HOLD_MEMORY)
什么是“DtlIntermRes”
以DtlIntermRes为关键字全网好像就《分布式计划执行时中间结果占用内存过大》提到了一下,分布式计划执行时中间结果全文应该是DTL interm results ,没有文档只能去githup上从开源版找找关键字. 也没找到具体的描述,但中间结果不同于sort area,hash area, 也可能包含节点间SQL执行过程中分布式执行计划在不同节点的数据缓存?我不确认。
class ObDTLMemProfileInfo : public ObSqlMemoryCallback
{
public:
ObDTLMemProfileInfo(const uint64_t tenant_id)
: allocator_(tenant_id),
profile_(ObSqlWorkAreaType::HASH_WORK_AREA),
sql_mem_processor_(profile_),
ref_count_(0), row_count_(0),
mutex_(common::ObLatchIds::SQL_MEMORY_MGR_MUTEX_LOCK) {}
~ObDTLMemProfileInfo() {}
// The local channel and the rpc channel may modify the interm results concurrently,
// and these interme results may be linked to the same profile.
// Therefore, access to the profile needs to be protected by locks
// to prevent concurrent modification issues.
限制max_dtl_memory_size内存使用?
从上面看好像是max_tenant_memory_limit_size* max_mem_percent_ / 100, 没有独立的限制DTL的大小, 这内存区我无法确认对应oracle这种集中式数据库是什么内存区,朋友说应该是PGA,但它有没有像oracle pga_max_size,和tidb mem_quota_query limit参数限制, 发现只有ob_sql_work_area_percentage参数, 如果是PGA 那应该对应的是 ora-4030 ,但错误信息也没有什么提示,限制 tenant memory limit那应该是max_tenant_memory_limit_size(租户内存大小)
OB_INLINE int64_t ObDtlChannelMemManager::get_max_dtl_memory_size() { if (0 == max_mem_percent_) { get_max_mem_percent(); } return get_max_tenant_memory_limit_size() * max_mem_percent_ / 100; } OB_INLINE int64_t ObDtlChannelMemManager::get_max_tenant_memory_limit_size() { int ret = OB_SUCCESS; if (0 == memstore_limit_percent_) { get_memstore_limit_percentage_(); } int64_t percent_execpt_memstore = 100 - memstore_limit_percent_; return lib::get_tenant_memory_limit(tenant_id_) * percent_execpt_memstore / 100; } OB_INLINE bool ObDtlChannelMemManager::out_of_memory() { bool oom = false; int64_t used = get_used_memory_size(); int64_t max_dtl_memory_size = get_max_dtl_memory_size(); if (used > max_dtl_memory_size) { oom = true; } return oom; }
如当在一台 100 GB 的机器上启动一个 OceanBase 数据库实例时,memory_limit_percentage 和 memory_limit 参数的值是如何影响 OceanBase 数据库的内存上限的。
| 示例 | memory_limit_percentage | memory_limit | OceanBase 数据库内存上限 |
|---|---|---|---|
| 示例 1 | 80 | 0 | 80 GB |
| 示例 2 | 80 | 90 GB | 90 GB |
错误编码
static const _error _error_OB_ALLOCATE_MEMORY_FAILED = {
.error_name = "OB_ALLOCATE_MEMORY_FAILED",
.error_cause = "Internal Error",
.error_solution = "Contact OceanBase Support",
.mysql_errno = -1,
.sqlstate = "HY001",
.str_error = "No memory or reach tenant memory limit",
.str_user_error = "No memory or reach tenant memory limit",
.oracle_errno = 600,
.oracle_str_error = "ORA-00600: internal error code, arguments: -4013, No memory or reach tenant memory limit",
.oracle_str_user_error = "ORA-00600: internal error code, arguments: -4013, No memory or reach tenant memory limit",
.ob_str_error = "OBE-00600: internal error code, arguments: -4013, No memory or reach tenant memory limit",
.ob_str_user_error = "OBE-00600: internal error code, arguments: -4013, No memory or reach tenant memory limit"
};
而在Oceanbase是当MemStore 就被用完,才返回用户报错 4030 (Over tenant memory limits)。看来还不是很一致。
分布式计划执行时中间结果占用内存过大案例描述DtlIntermRes内存大的问题原因是OB设计问题。所有中间结果的落盘是由一个后台线程完成的,写入速度较大时落盘跟不上,会导致占用内存越来越大。在读落盘的中间结果时,会申请内存存放数据,读完以后会释放内存释。为了避免频繁申请释放内存,这里做了优化,不会真正把内存释放掉,而是放入 free_list_ 中等待后续复用。导致 free_list_ 中的内存没有得到复用,因此导致使用的内存越来越多。该案例与我们的案例现象较接近.
hint /*+ parallel(2) */ 开启并行,并行度大于 1 时是流式执行,不会写中间结果。Ora-600 4013 和4030的区别
错误码 4013 的错误信息如下。
ERROR 4013 ( HY001 ): No memory or reach tenant memory limit
该错误码表示各个模块内存不足,例如 working area 不足。出现该问题的可能原因是编译和执行模块内存不足。此时 MemStore 并没有占满,仅仅是各个模块内存不足导致的报错。
错误码 4030 的错误信息如下。
ERROR 4030 ( HY000 ): Over tenant memory limits
该错误码表示 MemStore 内存不足,该错误通常发生在 INSERT、UPDATE、DELETE 语句及 table_scan 动作等 MemStore 操作上,此时错误的日志信息不是 ERROR 级别,而是 WARN 级别。
小结
因为没有日志和精力去定位该问题,更多也是没有太多的资料,当前的知识库或者是相比Oracle MOS 问题的描述还不是很透明或详细,不过我整理了好像个人能力有限也只到这个地步,这是所有国产库都存在知识库生态不足的问题,不过OB的文档相比已经是较全面的,更多可参考官方在线文档4013 内存爆问题的排查.

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~


对不起,这篇文章暂时关闭评论。