在PostgreSQL中主键使用 UUIDs vs. bigserial
在关系数据库中,每个表都需要一个主键,能够识别单个表行非常重要。做为主键使用UUID还是整数序列是一直有人讨论的话题,在oracle、Postgresq、MySQL、Sql Server(GUID) 都有类似的对象, 那应该使用整数( serials, sequences)还是 UUID 作为主键?在大数据集时性能上存在一些差异,同时还有一些空间、安全因素值得注意。
UUID
之前在《PostgreSQL生成UUID函数的性能区别》整理过uuid的几个版本, 当我们谈论 UUID 时,我们经常谈论 V4 UUID,, UUID 是 128 位序列,以十六进制编码的字符串形式规范表示,习惯于将它们视为字符串,格式如下“dfc9ea7d-486e-37a7-898d-5a065d19078e”,整个 UUID 字节序列是随机生成的,而不是使用基于时钟序列或其他任何东西的算法。
CREATE TABLE has_uuid_pkey (
id uuid DEFAULT gen_random_uuid() PRIMARY KEY,
...
);注意事项
- 由于 V4 UUID 是随机的,因此新条目可能会插入索引中的任何位置(最常见的是 BTREE)。这意味着必须将更多的页面引入内存和更多的缓存未命中。而如果使用bigserial,因为所有新数字都是紧密连续的,所以索引几乎总是在接近末尾的少数页面上运行。
- 与此相关,由于 UUID 会写入不同位置的各页面,因此这些修改后的页面都需要发送预写日志 (WAL) 进行复制。这导致了放大效应,需要写入更多的 WAL,这意味着需要跨网络链接复制更多的数据,并且增加了生产中不稳定的可能性。
- 表存储上也会占用更多的空间,UUID是128位,而是64-bit integer两倍的空间。
在较小的规模上,UUID不太可能造成太大的麻烦,不会夸张的那么糟糕,尤其是在应用得当的情况下。Postgres 非常高效,使用 UUID 大多没问题。但是,在执行大量插入的热系统中,效果非常显著。
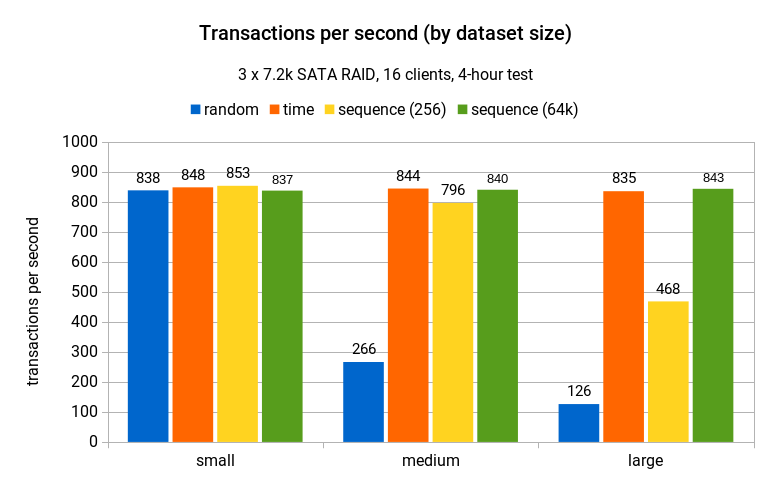
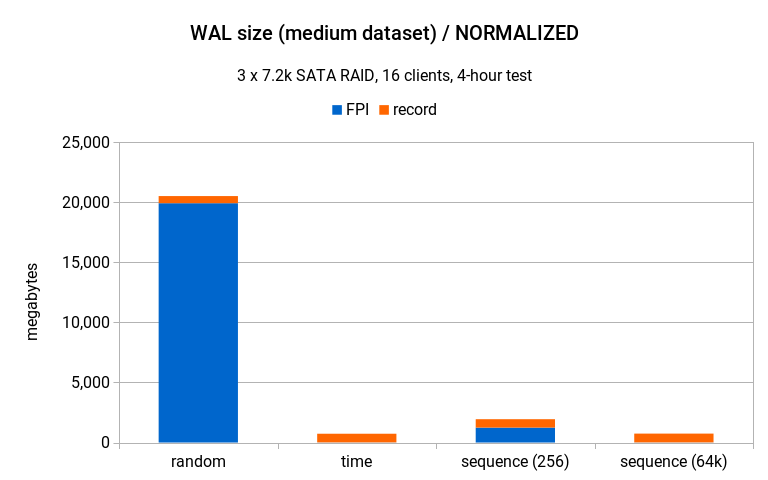
(这些由 2nd Quadrant 提供。“small” 数据集在空表上进行交易,“medium” 适合内存,“large” 超出内存。在第一张图中,可以看到中型/大型数据集的蓝色条形(随机 UUID)如何比其他策略小得多,这意味着可以插入的次数更少。在第二个阶段,了解 random 如何产生数量级以上的 WAL 体积。实际上,这些比较比 UUID 与 bigserial 要复杂一些)
bigserial
bigserial,它是一个 64 位整数,而不仅仅是 serial,它是一个 32 位整数。在当今世界,由于 64 位架构无处不在,因此从来没有充分的理由使用 32 位序列而不是 64 位序列。建议始终使用使用 bigserial。整数对人类更友好,对于数值的记忆或比较远比UUID 的字符更有遍历。新的插入将发生在索引中相对较少的页面上,从而允许更多的事务吞吐量,并创建最小的 WAL 。性能提高,运营风险降低。
CREATE TABLE uses_serial (
id bigserial PRIMARY KEY,
...
注意事项
恶意用户可能会利用它们来尝试基于 ID 迭代或冲突的攻击。
IDENTITY
IDENTITY具有与bigserial相同的性能特征,但它在 SQL 方言中更加标准,更重要的是,如果插入具有任意值的行,它将出错 – 所有插入都必须从默认序列中获取值。尽管它对大多数日常使用几乎没有影响.
ULID
这个概念在 Postgres 之外的推广是 ULID(“通用唯一字典排序标识符”)。它们是与 UUID 兼容的 128 位类型,将前 48 位保留用于时间戳,其余位用于随机性,它们以 base-32 而不是十六进制编码,这就是为什么字符串表示形式看起来与 UUID 不同的原因
01AN4Z07BY 79KA1307SR9X4MV3 |----------| |----------------| Timestamp Randomness 48bits 80bits
时间戳是自 Unix 纪元以来以毫秒为单位的时间整数,48 位足以在公元 10,889 年之前不会溢出。ULID 与上面的 Postgres UUID 生成器的不同之处在于,前置加载的位始终递增且从不回收。这有一个很好的优势,即与彼此相比,在任何地方创建的所有 ULID 都可以很好地排序。
SEQUENCE
序列是一个数据库对象,其唯一目的是生成唯一的数字,它使用递增的内部 counter 来执行此操作。
|
1
|
SELECT nextval(‘sequence_name’);
|
小结:
没有压倒性的胜利者,都有一些适合的场景.
考虑插入将如何影响索引和 WAL,并旨在实现合理的性能,请使用bigserial
UUID对用户不透明的 ID(即不是序列)对安全性和业务有益。它们可以防止迭代/冲突攻击,并且很难推断出任何数据、存在的数据量或生成数据的速率。

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~


对不起,这篇文章暂时关闭评论。